




Donald Knuth Is the Root of All Premature Optimization
This article is about something profound that a brilliant young professor at Stanford wrote nearly 45 years ago, and now we’re all stuck with it.
TL;DR
The idea, basically, is that even though optimization of computer software to execute faster is a noble goal, with tangible benefits, this costs time and effort up front, and therefore the decision to do so should not be made on whims and intuition, but instead should be made after some kind of analysis to show that it has net positive benefit.
This guidance has become something of a platitude, however, and is now used overwhelmingly as a rule that must be followed to the letter, without exception. We will explore the ambiguity surrounding optimization.
There — now I’ve done something I rarely do in my articles, which is to give a bland summary of what I’m going to write, in less than 100 words.
L;R
In my last article, I talked about Amdahl’s Law, and why it’s overly pessimistic about the effects of optimization on the execution time of part of a set of tasks. Maybe you have to speed up one task 400% in order to get a 20% decrease in total execution time, but knowing this dismal fact shouldn’t necessarily stop you from doing so.
That article was much more polarizing than I expected. Some people loved the title; others hated the title, but really liked the article; others hated the article itself, and said it was far too long. I suppose some people got tired of all the Kittens Game references. I don’t really care what you think about that article or this one. I write publicly because I have something to say, and because some people seem to find my articles educational and entertaining. If you don’t want to be subjected to another long article by yours truly, exit now and go read Twitter posts or the latest Hacker News posting from Wired or The Verge. Or jump down to the Wrapup section and get the 30-second version. Or read one of the other related articles on this subject, most of which are shorter. Whatever.
Anyway, now I’m going to head in a different direction from Amdahl’s Law, and talk about cases when you shouldn’t optimize. Or at least that’s where I’ll start out. Who knows where I’ll end up. (Oh — and a warning: this article does contain a few references to kittens, though not as many as the last time.)
But first, let me talk about one of my pet peeves. You see, about eight years ago… hmm, maybe there’s a better way to tell this.
An American Tale of Three Dons
Once upon a time, there was a young software programmer named Don Bluth, who escaped from persecution, wasted effort, and endless memory management woes in the land of C++ on Microsoft Windows, never to return.

He immigrated to a new country, where languages like Java and Python were used, and while trying to find a place to settle, and get his bearings, encountered Stack Overflow. Here he finally realized he was not alone, and he could ask many questions, and learn, unlike the dark ages in his old country, where he was trapped by himself with only a few marginally-helpful books. So ask he did, and it was very fruitful.
Now along the way, Don Bluth met a number of odd characters. Many of them were very helpful, such as Jon Skeet. But some were not. One was the Soup Nazi, who was generally mean and unreasonable. Another was the Phantom Downvoter, who would throw -1 votes without comment, leaving chaos and disapproval in his wake. There was the Fastest Gun in the West, who was always the first one to answer, even though sometimes he got things wrong, and discouraged those who took their time. And there were the Clueless Students, who, desperate for help, typed in their homework questions verbatim, wanting someone to answer, and causing irritation for those who were not clueless.
Then there was Don Not, a part-time deputy sheriff and part-time software engineer from somewhere in North Carolina.

Don Not would answer questions from programmers who were trying to make their programs better, and tell them one of two things:
-
You’re asking the wrong question, what are you really trying to do? (Sometimes he would just yell “XY problem!” and run off, his police revolver discharging in the process.)
-
What you’re trying to do is not worth doing, it’s just going to make your life harder.
Don Not always had good intentions, and many times he was right, but Don Bluth didn’t like the way Don Not behaved; he was just a source of discouragement, and Don Bluth thought he could be nicer and more helpful, especially for someone such as a deputy sheriff in a position of authority.
What annoyed Don Bluth about him most of all, though, were two particular tendencies:
-
When Don Not’s advice was wrong
-
When Don Not told someone that Premature optimization is the root of all evil as a way of not answering their question, and instead saying that they were trying to spend a lot of effort on something that really didn’t matter much. He did this hundreds of times.
Here is one example — in one of Don Not’s answers, he said:
Always use whatever is the clearest. Anything else you do is trying to outsmart the compiler. If the compiler is at all intelligent, it will do the best to optimize the result, but nothing can make the next guy not hate you for your crappy bitshifting solution (I love bit manipulation by the way, it’s fun. But fun != readable)
Premature optimization is the root of all evil. Always remember the three rules of optimization!
- Don’t optimize.
- If you are an expert, see rule #1
If you are an expert and can justify the need, then use the following procedure:
- Code it unoptimized
- determine how fast is “Fast enough”–Note which user requirement/story requires that metric.
- Write a speed test
- Test existing code–If it’s fast enough, you’re done.
- Recode it optimized
- Test optimized code. IF it doesn’t meet the metric, throw it away and keep the original.
- If it meets the test, keep the original code in as comments
Also, doing things like removing inner loops when they aren’t required or choosing a linked list over an array for an insertion sort are not optimizations, just programming.
Here’s another answer, in its entirety, in which he responded to a question about which was better, using text.startswith('a') or text[0]=='a':
The stock phrase for the questiom is: “Premature optimization is the root of all evil”.
Or this answer, also in its entirety, responding to someone who was concerned about excessive connections to a database:
Premature optimization is the root of all evil.
Get your app rolled out. Once real people use it for real purposes, you can do benchmarks to see where you really need to optimize.
Don Bluth knew that Don Not was quoting Don Knuth out of context.

Don Bluth felt that Don Not should have at least stated the entire sentence of this Don Knuth quote:
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.
But even more importantly, Don Bluth felt this Don Knuth quote deserved to be stated in its larger context — it was part of a classic December 1974 article, Structured programming with go to statements, in ACM’s journal Computing Surveys, in which Knuth entered the debate of whether goto statements should be part of well-designed computer programs, and discussed various pro and con arguments. One of the issues was efficiency, and he pointed out an example of loop unrolling, saying
The improvement in speed from Example 2 to Example 2a is only about 12%, and many people would pronounce that insignificant. The conventional wisdom shared by many of today’s software engineers calls for ignoring efficiency in the small; but I believe this is simply an overreaction to the abuses they see being practiced by penny-wise-and-pound-foolish programmers, who can’t debug or maintain their “optimized” programs. In established engineering disciplines a 12% improvement, easily obtained, is never considered marginal; and I believe the same viewpoint should prevail in software engineering. Of course I wouldn’t bother making such optimizations on a one-shot job, but when it’s a question of preparing quality programs, I don’t want to restrict myself to tools that deny me such efficiencies.
There is no doubt that the grail of efficiency leads to abuse. Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.
Yet we should not pass up our opportunities in that critical 3%. A good programmer will not be lulled into complacency by such reasoning, he will be wise to look carefully at the critical code; but only after that code has been identified. It is often a mistake to make a priori judgments about what parts of a program are really critical, since the universal experience of programmers who have been using measurement tools has been that their intuitive guesses fail. After working with such tools for seven years, I’ve become convinced that all compilers written from now on should be designed to provide all programmers with feedback indicating what parts of their programs are costing the most; indeed, this feedback should be supplied automatically unless it has been specifically turned off.
After a while, Don Bluth started arguing with Don Not about his propensity for quoting Premature optimization is the root of all evil as a sort of prerecorded answer which implied the questions were invalid. Don Bluth was upset, and felt that there were good reasons to optimize, even if they seemed premature.
So who was right? Don Bluth? Don Not? Or Don Knuth?
Sun Tzu and Hobart Dishwashers
Before we try to answer that, consider the difference between tactics and strategy.
“All men can see the tactics whereby I conquer, but what none can see is the strategy out of which victory is evolved.” — Sun Tzu, The Art of War
Strategy is the overall approach used to meet a goal. Tactics are individual actions that assist in bringing success. They may have very little to do with each other. Let’s say you are working in a kitchen at a summer camp, and your goal is to get everything cleaned up and put away as fast as practical, so you can move on to the next task, whether it’s washing windows or bringing out the trash, or just lying on the grass and watching the clouds float by. “Everything” here might include 60-80 trays of dirty dishes, along with some huge commercial pots and pans caked with burnt food, and various measuring cups, graters, knives, whisks, bread pans, and what-not. Maybe there are four or five other people working with you, and you and another guy are running the Hobart dishwasher. This is a gleaming stainless steel apparatus topped by a stainless steel cube about 60cm wide, with a big lever on the side that lifts up two doors that comprise the left and right sides of the cube. One is the in door, and one is the out door. The in door is typically connected via a stainless steel shelf to a sink and sprayer; the out door is typically connected to another stainless steel shelf. The bottom of the Hobart’s working volume is open and looks down into a rotating sprayer, and along the edges are two metal rails that allow plastic racks to slide from the incoming shelf through the dishwasher and then to the outgoing shelf. If you’re working at the sink, you slide in a big rack of dirty dishes, pull down the lever to close the doors and start the machine, and in about two or three minutes the dishwasher goes through a wash, rinse, and sterilization cycle. Then the other guy pulls the rack out to let the dishes dry and put them away, while you get another batch of dishes ready. Tactics in the kitchen might go like this:
- Do your designated job, and stay out of each other’s way
- Two people work at the Hobart, one at the sink handling incoming items and the other handling outgoing items to let them dry and put away.
- Incoming items need to be washed at the sink to get the majority of food off. (The Hobart isn’t going to take off burnt egg and cheese for you.)
- Put cups, bowls, etc. facing downwards, because the Hobart sprays water up from the bottom
- The person handling outgoing items needs to wear heavy rubber gloves; the sterilization cycle rinses with water that is around 82 - 88° C (180 - 190° F), and you can be badly burned by hot metal pots or even the water vapor
- Watch the Hobart closely when it’s on, so you can take items out of it as soon as the sterilization cycle is complete
- The person at the sink needs to be aware of the person handling outgoing items, to slow down if there’s a backlog
- Fill the Hobart reasonably full, but not too full so that some of the surfaces don’t get cleaned
- Silverware gets put into a stainless-steel mesh silverware basket; fill it up so you can put it through the Hobart in large batches
- Save the trays until the end
- When drying trays, stack them alternating crosswise and face down so the remaining water vapor drips off
- Make sure the floor stays dry, otherwise you can slip and fall
Strategy is a different thing altogether. There isn’t much of it in cleaning up a kitchen; all I can think of from my experience is
- dividing up the jobs into reasonable tasks
- making sure the kitchen is setup so that all dishes, kitchenware, and supplies can be stored in an organized manner, and it is conducive to being cleaned quickly
- making sure the kitchen workers get along; animosity among coworkers is poisonous
- spreading out the dishwasher workload where possible to make use of available time (for example, send pots/pans/etc. used in cooking to be cleaned as soon as food preparation is complete, before serving, and if there’s more people than usual at the meal, start washing dishes as soon as possible after the first people are done eating)
The responsibility for strategy lies with whoever is in charge of the kitchen, whereas everyone doing the work needs to be aware of the best tactics.
So what the heck does a Hobart dishwasher have to do with programming? Not a whole lot, apparently, so let’s get back to Don Bluth and Don Not and Don Knuth.
Don Knuth Is Always Right, Say About 97% of the Time
Knuth is a first-rate mathematician and computer scientist who has been writing and curating The Art of Computer Programming over the past 55 years. The foundations of computer science are discussed in depth there. He was also one of the early experts on compilers. So when Donald Knuth says you should forget about small efficiencies 97% of the time, you should take this advice very seriously.
Both Knuth and Not are saying that optimization can be a wasteful effort that yields little (sometimes negative!) benefit, and both of them state that optimization cannot be considered worthwhile without measurement. It’s foolhardy to say “I’m going to replace this \( O(n^2) \) bubble sort with an \( O(n \log n) \) quicksort” without understanding quantitatively what effect that decision will have on the performance of the resulting program.
So let’s consider three simple examples.
Here is one that is relevant to one of the Stack Overflow questions I referenced earlier, that asked whether it was better to use floating-point multiplication or division for performance reasons:
y = x / 2.0; // or... y = x * 0.5;Assuming we’re using the standard operators provided with the language, which one has better performance?
To understand the answer quantitatively, you need to measure something within a specific language implementation. There’s not a general answer, although Don Not’s opinion in this case was that this was premature optimization. If the language implementation maps the multiplication and division to a hardware instruction, and it is done on a processor where floating-point multiplication and division take the same amount of time, then it wouldn’t matter, and the more readable option would be the better one. Even if multiplication is faster, and making such a change did cause an improvement in performance, it wouldn’t be worth doing unless there was substantial evidence that a program was unacceptably slow and the division was a significant performance bottleneck.
On today’s modern processors, the performance varies, and floating-point hardware division is usually expected to be slightly slower; one study on several processors showed a speed handicap in the 1.1 - 3.0 range. Your Mileage May Vary, and of course it depends on the particular context.
I work with Microchip dsPIC33E devices, which have no hardware floating-point arithmetic features, and rely on software libraries for floating-point arithmetic. I took a few minutes to measure the execution time of 32-bit floating-point multiply and divide operations, with the MPLAB X simulator, for dsPIC33E devices using the XC16 1.26 compiler at -O1 optimization. Here’s the source code:
f.c:
float f1(float x)
{
return x / 3.0f;
}
float f2(float x)
{
return x * (1.0f/3.0f);
}
main.c:
extern float f1(float x);
extern float f2(float x);
float result1, result2;
int main()
{
float x = 13.0f;
result1 = f1(x);
result2 = f2(x);
return 0;
}
and if you look at the compiler output of processing f.c it contains the following (with labels stripped off):
_f1:
mov #0,w2
mov #16448,w3
rcall ___divsf3
return
_f2:
mov #43691,w2
mov #16042,w3
rcall ___mulsf3
return
The call to f1(), which uses floating-point division, took 511 cycles and the call to f2(), which uses floating-point multiplication, took 169 cycles, about a 3:1 ratio. In this case, the results were identical (0x408AAAAB ≈ 4.3333335), but because 1/3 isn’t exactly representable in floating-point, multiplying by (1/3.0) and dividing by 3.0 aren’t guaranteed to have the exact same result. In fact, I ran some Python code to investigate quickly whether there were any inputs that produced different outputs. It looks like there’s about a 1/3 chance of this happening:
import numpy as np
xlist = np.arange(1,2,0.0001).astype(np.float32)
def f1(x):
return x / np.float32(3)
def f2(x):
onethird = np.float32(1) / np.float32(3)
return x * onethird
y1list = f1(xlist)
y2list = f2(xlist)
print '# of values where f1(x) == f2(x): ', np.sum(y1list == y2list)
print '# of values where f1(x) != f2(x): ', np.sum(y1list != y2list)
max_rel_error = (np.abs(y1list-y2list)/y2list).max()
print 'Max relative error: %g = 2^(%f)' % (max_rel_error, np.log2(max_rel_error))
print 'Max binary representation error: ', np.abs(y1list.view(np.int32)-y2list.view(np.int32)).max()
print 'Example of discrepancy:'
for x,y1,y2 in zip(xlist,y1list,y2list):
if y1 != y2:
for k,v in [('x',x),('y1',y1),('y2',y2)]:
print '%s = %.8f (%04x)' % (k,v,v.view(np.int32))
break# of values where f1(x) == f2(x): 6670 # of values where f1(x) != f2(x): 3330 Max relative error: 1.19201e-07 = 2^(-23.000095) Max binary representation error: 1 Example of discrepancy: x = 1.00010002 (3f800347) y1 = 0.33336666 (3eaaaf09) y2 = 0.33336669 (3eaaaf0a)
Sure enough, 1.0001f (with binary representation 3f800347) produces different answers on the dsPIC33E for these two methods. I am sure there is a way to prove that if the answers are different, then the difference is at most 1 ulp, and furthermore, that both are within 1 ulp of the exact answer, but that’s beyond my mastery of floating-point arithmetic. In any case, for my purposes such a discrepancy wouldn’t matter — it’s close enough for the kind of calculations I do* — so replacing floating-point division by a constant, with floating-point multiplication by that constant’s reciprocal, would be a performance optimization I would strongly consider:
- it’s an easy optimization for the programmer to create, taking only a second or two
- it poses little or no risk to correctness
- it poses little or no risk to readability or maintainability
- it is measurably faster
(*For the record, here’s the fine print: I work on motor control software, and the kind of end-to-end numerical accuracy I need is on the order of 0.1% of fullscale input range, which is smaller than errors introduced by typical analog circuitry. In a recent article I analyzed this error for a 10-bit ADC and found that worst-case error including DNL and INL was 0.244% of fullscale. There are particular types of calculations which do need to be more accurate, because numerical sensitivity is high, but these are rare in my field. If you’re working with iterative matrix or matrix-like calculations, such as an FFT, or an observer or Kalman filter, you need to be more careful and figure out how repeated intermediate calculations affect your results, before you dismiss accuracy requirements. The easy thing to do is just throw double-precision floating-point calculations at your problem, as long as the condition number is low.)
There’s still the point of view that, unless the program in question is unacceptably slow, then any optimization is premature and wasted effort. Let’s hold off on that issue for a moment, and look at another quantitative example.
To Build or Not to Build: That is the Question
Of course, optimization (and premature optimization) isn’t limited to programming; for a second example we’ll take another look at the Kittens Game, which I used frequently in my previous article on Amdahl’s Law.
Suppose I have the following situation:
- I have 5000 slabs at the moment
- I am trying to produce 300,000 slabs, which I need for another upgrade
- I have a bunch of miner kittens and upgrades, producing 16973 minerals per second
- My crafting bonus is +618% (multiplier of 7.18), so I can transform 250 minerals into 7.18 slabs
- The minerals bonus from buildings is +2095% (multiplier of 21.95)
- I have 13 quarries, and can build a 14th quarry with an additional additive minerals bonus of 35% for 228.048 scaffolds, 684.144 steel, and 4560.959 slabs
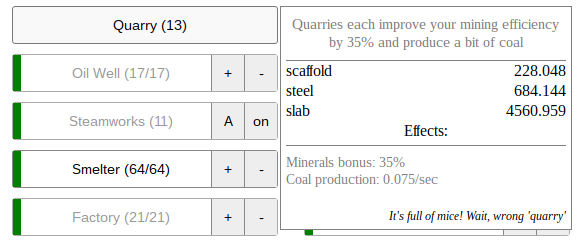
Will building a 14th quarry get me to my goal of 300K slabs faster?
Maybe it will; after all, if I build a 14th quarry, then my minerals bonus will increase and I can produce minerals at a faster rate, which means I can produce slabs (which are converted from minerals) at a faster rate.
But perhaps it will take longer, because the quarry costs me 4561 slabs to build, and that puts me further from my goal of 300,000 slabs.
Let’s figure this out. We’re going to look at Return on Investment (ROI) of this quarry dilemma. We basically have two options, keep things as is, or build a 14th quarry.
- As is: 295,000 slabs will take \( 295\text{K} / 7.18 \times 250 = 10.272\text{M} \) minerals, which will take 605.2 seconds (a little over 10 minutes) to produce
- Build 14th quarry:
- Minerals building multiplier will increase from +2095% to +2130%, increasing our production to 17244 minerals per second
- We’ll need to produce 295,000 + 4561 = 299561 slabs to make up for the slabs we have to spend for the 14th quarry
- \( 299561 / 7.18 \times 250 = 10.430\text{M} \) minerals, which will take 604.9 seconds to produce.
By building a 14th quarry, we’ll decrease the time to our goal from 605.2 seconds to 604.9 seconds, saving 0.3 seconds, just barely making it past the breakeven point. Yes, it’s worth building the 14th quarry, just barely. If we needed 100K slabs, rather than 300K slabs, for some other urgent purchase, it would be better to postpone building the quarry until after our 100K slabs are ready. If we needed 1M slabs, the 14th quarry would be worth building; it would make minerals production about 1.6% (= 2230/2195) faster.
The breakeven point happens when we recover the 4561 slabs we spent, because of the extra production the 14th quarry brings, of 17244 - 16973 = 271 additional minerals per second. 4561 slabs can be crafted from \( 4561 / 7.18 \times 250 = 158809 \) minerals, which takes 158809 / 271 = 586 seconds.
The difference between 13 and 14 quarries in this case is very slight, because we’ve increased the production rate by 1.6%. Here’s a graph of available slabs over time with the two cases; the red line is 13 quarries and the black line is 14:
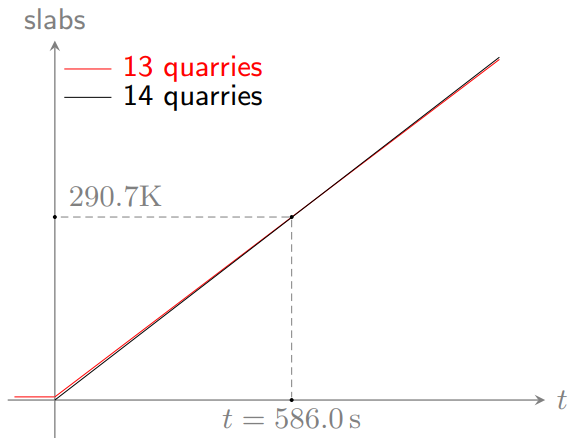
(For the record, on this particular run of the game, the 15th quarry costs 5126 slabs, adding a further 271 minerals per second, which will allow us to recover the 5126 slabs in 659 seconds, a little bit longer than for the case of the 14th quarry. The Kittens Game uses this philosophy of “diminishing returns” to make sure that game play doesn’t zoom up exponentially in the player’s favor.)
This example isn’t so bad; a 10-minute return on investment is a pretty quick one. ROI in the finance world is usually measured in percent per year (and people will be very interested when you can guarantee 10% ROI), and here we are with a 10% per minute ROI. It is a computer game, after all.
Others in the Kittens Game are less productive; I usually stop on Unicorn Pastures after the 15th one, but this time, just to see, I looked at Unicorn Pasture 16, which costs 7053.545 unicorns to build. Where do you find 0.545 unicorns? Well, each Unicorn Pasture produces 0.005 unicorns per second as a base rate, before production bonuses. At this rate, recouping the investment in a 16th Unicorn Pasture would take about 16 days. Even with the production bonuses in my current game, where I’m getting about 0.324 unicorns per second per pasture, the payback period is 7054/0.324 = about 21770 seconds = a little over 6 hours. Meh. I guess it’s worth it. But the 17th pasture costs over 12000 unicorns. Prices increase by 75% with each new pasture, so you quickly hit a wall, where there are other things you can do in the game that would be better uses of extra unicorns.
There, now you’ve read the last of my Kittens Game references, at least for this article.
Continuous Is As Continuous Does
So far these examples have dealt with binary choices: either we do something (use multiplication by a fixed reciprocal instead of division, build a 14th quarry) or we do not, and one of the two alternatives is better. This isn’t always the case. Occasionally we have to choose a parameter from among a continuous set of alternatives: for example, the choice of a communications timeout, which could be 1 second or 10 seconds or 37.42345601 seconds, or a buffer or cache size.
The third example I will present is a purely mathematical optimization exercise. The difference between optimization in the mathematical sense, and in the engineering sense, is that mathematical optimization is just a matter of stating a problem in quantitative terms, and finding an appropriate minimum or maximum. Engineering optimization, on the other hand, usually means going through mathematical optimization and then applying the result, and there’s all these messy things like measurement and designing and building and testing and what-not, all of which are actions that send pure mathematicians scurrying away to find the next problem.
Let’s consider the following function:
$$f(x) = \frac{a}{1+(x+1)^2} - \frac{a}{1+(x-1)^2} + \frac{b}{1+x^2}$$
(If you hate pure mathematics, just pretend that \( f(x) \) is your net profit from running a business that deals in… I don’t know… energy futures contracts, kind of like Enron, where \( x \) is the number of gigawatt-hours you buy if \( x \) is positive, or sell if \( x \) is negative, and \( a \) and \( b \) are prices of key energy commodities like the price of oil and natural gas. Or just pretend that \( f(x) \) is your net profit from running an ice cream business. Heck, just forget the equation altogether and go eat some ice cream, and remember that \( f(x) \) is PROFIT so you want to maximize it.)
Furthermore, \( a \) and \( b \) are functions of a single parameter \( \zeta \) between 0 and 1:
$$\begin{align} a &= \zeta - 0.5 \cr b &= \frac{1}{6}\zeta(1 - \zeta) \end{align}$$
The optimization problem is that we want to find the value of \( x \) that maximizes \( f(x) \). If we graph \( f(x) \) for various values of \( \zeta \) we can get a sense of what’s going on:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
def f(x,zeta):
a = zeta-0.5
b = (zeta-zeta**2)/6.0
return a/(1+(x+1)**2) - a/(1+(x-1)**2) + b/(1+x**2)
zeta_list = np.arange(0,1.01,0.1)
x = np.arange(-3,3,0.01)
for zeta in zeta_list:
plt.plot(x,f(x,zeta))
for x1 in [-1.05,1.05]:
plt.text(x1,f(x1,zeta),'%.1f' % zeta,
fontsize=10,
verticalalignment='bottom',
horizontalalignment='center')
plt.title('$f(x)$ as parameter $\\zeta$ varies')
plt.grid('on')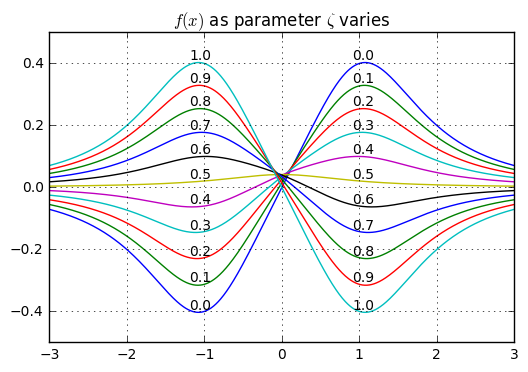
In a qualitative sense:
- the best choice for \( x \) is near \( x=1 \) if \( \zeta \) is less than 0.5
- the best choice for \( x \) is near \( x=-1 \) if \( \zeta \) is greater than 0.5
- when \( \zeta \) is close to 0.5, the best choice for \( x \) is near \( x=0 \), where there’s a very small increase in \( f(x) \) relative to other choices of \( x \)
Mathematically we can look at \( \frac{df}{dx} \) and find out when it is zero:
$$\begin{align} \frac{df}{dx} &= \frac{-2a(x+1)}{\left(1+ (x+1)^2\right)^2} - \frac{-2a(x-1)}{\left(1+ (x-1)^2\right)^2} - \frac{2bx}{\left(1+x^2\right)^2} \cr &= (1-2\zeta)\left(\frac{x+1}{\left(1+ (x+1)^2\right)^2} - \frac{x-1}{\left(1+ (x-1)^2\right)^2} \right) - \frac{\frac{1}{3}(\zeta - \zeta^2)x}{\left(1+x^2\right)^2} \end{align}$$
And if you want to play a game of Grungy Algebra! you can solve for \( x \) as a function of \( \zeta \). Or just brute-force it numerically by using a solver function like scipy.optimize.minimize_scalar:
import scipy.optimize
zeta = np.arange(0,1.001,0.01)
x_opt = []
for zeta_i in zeta:
x_i = scipy.optimize.minimize_scalar(
lambda x: -f(x,zeta_i),
bounds=(-2,2)).x
x_opt.append(x_i)
x_opt = np.array(x_opt)
plt.plot(zeta,x_opt)
plt.xlabel('zeta')
plt.ylabel('optimal value of x')
plt.grid('on')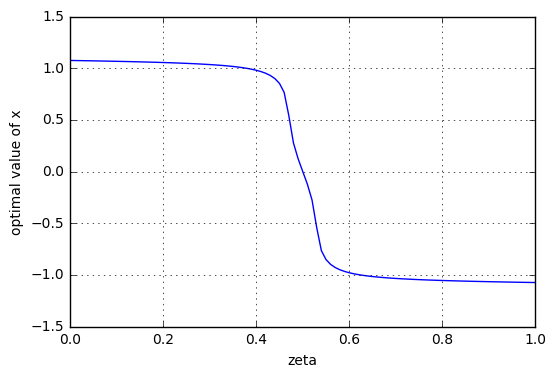
There we go, not very interesting. You tell me a value of \( \zeta \), I can tell you the optimal value of \( x \) to maximize \( f(x) \). Yippee.
We’ll come back to this example again; the interesting stuff comes later.
Measurement and Estimation
One important point, which I hope you noticed in the first two of these examples, is that in order to be sure there had a tangible benefit from optimization, I went through some measurement or quantitative analysis to figure out what that benefit would be.
Sometimes you can just build it and try it. That’s the nice thing about software; the cost of running experiments is generally very low. Measure a tight loop of 100 million multiply operations? No problem! In this case Don Not is right: just build it, don’t bother trying to optimize it until after you’ve done it the easy way and measured that approach.
Other times, it’s not practical to try the exact thing we’re going to build. Let’s say I’m making a program that displays a list of 1000 stock symbols and their prices, in real-time, with some sort of trend graph indicator, and I have to decide which graphing library (let’s say JFreeChart vs. JChart2D) is going to work for me, before I invest a lot of time into that library. If I spend 3 months making my program using one library, and later find out that it is too slow, I might have to spend several weeks converting it to use the other library, since the interfaces to these libraries are very different. So instead, I might spend a day or two to create a simple test program using fake data, then run it through its paces to see how it does trying to keep up with lots of changes. Yes, it costs me time to do this, but the cost of a simple performance trial is much less expensive than trying it out on the real thing.
Engineers in other fields, especially civil engineering or aerospace engineering or nuclear engineering, are used to running simulations or building models for tests to ensure that their design is robust. In part, this is because the cost of making errors is so high. When an aerospace engineer designs an airplane wing for commercial aircraft, they don’t just chuck in a standard airplane wing into the design, so someone can build it and then see if it’s adequate. If it’s not, that’s a multimillion-dollar mistake! So they run simulations and analyze and build scale models in a wind tunnel and rely on decades of past engineering work in order to come up with a good wing design.
But software is different, because the cost to swap out some piece of it is very small, at least in theory. Does PostgreSQL perform better than MySQL? No problem, just swap out the database layer! Except, well, when some little minor detail is incompatible with the way you’re using it, and it takes a little longer.
Okay, let’s step back a bit.
Let’s assume that you have some potential performance improvement \( p_1 \), and it can be measured. Presumably there’s more than one potential performance improvement, so you’ve got a number of different options \( p_2, p_3, \dots p_n \) — which aren’t necessarily exclusive, and may not have independent effects on the overall timing. For example, I could pursue \( p_1 \) and \( p_5 \) and \( p_7 \), and the execution time savings might be different than the sum of the savings from individual improvements \( p_1 \), \( p_5 \), and \( p_7 \), perhaps because \( p_1 \) interferes with the other two. Theoretically you could write a time-of-execution equation \( T = f(P) \) where \( P \) is the set of performance improvements used in any particular case, and you could enumerate \( f(P) \) for each possible combination....
Game Over, Thanks for Playing
While you’re perfecting your program to be the most optimal, your competitor doesn’t bother trying to optimize, and gets his version of software on the market first, grabs all the market share, and puts you out of business.
Don Not is often correct, but he doesn’t do a good job articulating why. When we looked at Amdahl’s Law last time, one thing we saw was that a lot of small improvements can add up. So even if an improvement is small, it may be worth doing. But this assumes that an improvement exists on its own: I can either keep things as is, or add performance improvement \( p_k \), which will improve things by some factor… and in that case, how could I not make this improvement? Usually when you’re working on an engineering design, this never holds true; there are only tradeoffs, and each improvement has an associated cost. Yes, I can make Widget X faster by 23.2%, but to do so I will have to spend somewhere between 4 and 36 man-hours, and it will make it slightly harder to use, and it will raise the risk that there’s a programming error from something like 0.01% to 0.1%.
As programmers, we tend to have vision problems: we see the potential improvement much more clearly than the cost tradeoffs that come with it. Hence the advice that premature optimization is evil. But just remembering this advice without the reasoning behind it (and the surrounding context of the Knuth article) is cargo cult science.
Chances are, if you’re a software engineer, you work with an already-impossible-to-meet deadline, so the cost of extra development time for performance improvements is extremely high, and you’ll need to ignore those urges to optimize. Plus in many cases it doesn’t matter. If I’m working on some software where the user clicks a button, my function runs, and then a window pops up, and I have a choice of implementation that looks like this:
- unoptimized performance: 30 milliseconds
- optimized performance: 23 milliseconds
then a person’s reaction time isn’t fast enough to notice the difference, and the optimization has no human-measurable benefit.
If you’re lucky enough to have some room in your schedule, the next time you have an idea for performance improvements, ignore this pessimism for a bit: go through the exercise of a cost-benefit analysis (what’s the performance improvement? how long will it take to implement it? what drawbacks does it have?) and bounce it off your colleagues, and you’ll start to be more realistic about performance improvements.
Wait a Minute: If Donald Knuth Is Always Right About 97% of the Time, Doesn’t That Mean He’s Sometimes Wrong About 3% of the Time?
So when is Donald Knuth wrong? (And do I get a \$2.56 check for pointing this out?) I racked my brain trying to think of a situation in which his advice on optimization was inappropriate.
Let’s go over some cases where optimization matters:
- If you complete a working software prototype, and can measure your software’s execution speed, and it’s not adequate
- If you haven’t completed a working software prototype yet, but there’s strong evidence that it’s not going to be adequately fast
- If you have software that is adequate with modest inputs, but it doesn’t scale well, so that when it is given very large inputs, it will not be adequate*
- If you’re working on software whose value to the customer is correlated to its processing throughput and/or latency (mathematical computation, video rendering, real-time trading, etc.) — this is essentially the same as the previous point
- If there is significant risk of any of the preceding items being true
(*Side note: this occurs very often in computer simulations, and is the poster child for Gustafson’s Law, which we talked about last time. Strassen’s algorithm for matrix multiplication is a really good example. It’s a more complex improvement over the standard approach for matrix multiplication that has a slower order of growth, so it makes sense to apply when matrix sizes get large enough.)
Don Not’s philosophy seems to be that only the first of these is important. Keep the optimization blinders on, and don’t take them off until you run into a problem.
Don Knuth’s philosophy — at least as far as I can read into his article — is that all of these matter, but you need to have evidence first. And the last one is tricky. Because sometimes you don’t know whether you need to optimize something; there are uncertainties and risks and opinions but no definite answers.
There’s an idea in portfolio theory about risk and return. If you want a risk-free investment… well, there ain’t no such thing, but you could put your money into government bonds of stable countries. And you’d get a pretty low return, but the likelihood that you’d lose some of your money would be very low. Or you could put your money into a diverse mix of stocks, and the risk of losing some of your money is higher, but so is the likely return on your investment, and how this risk plays out depends on your time horizon. So if you have a retirement plan with a big investment firm, most likely they will ask how long your time horizon is (in other words, when you plan to retire) and then suggest a mix of stocks and bonds that gradually moves from more aggressive (stocks) to more conservative (bonds) over time.
An analogous situation is true for software development. There is risk in trying new things. Some of them may pay off, and some of them may go nowhere. I guess my point of view is that if you work in a programming job and you NEVER have any time to try something risky, because the schedule is always too urgent to meet, then you should probably find a different job. I figure if I spend 2-10% of my time on “risky” things, it’s worth it, especially since I can still meet my deadlines, and some of these attempts have really paid off over the long run. (I wouldn’t have gotten into motor drive design if I hadn’t taken such a risk… but that’s a story for another time.) So put speculative optimizations in that bucket — first make a quick estimate of whether they’re worth it, and unless there’s overwhelming evidence that they’re a complete waste of time, go ahead and try them out. If they do produce a useful benefit, then you’re ahead of the game. If not, or it’s negligible… well, then you learned something, and maybe after five or ten such attempts, you’ll have a better sense of when to avoid going on a wild goose chase for optimization’s sake.
So I guess here’s where the problems are:
Yet we should not pass up our opportunities in that critical 3%. A good programmer will not be lulled into complacency by such reasoning, he will be wise to look carefully at the critical code; but only after that code has been identified. It is often a mistake to make a priori judgments about what parts of a program are really critical, since the universal experience of programmers who have been using measurement tools has been that their intuitive guesses fail.
My take on it is that, in some cases, it may be uncertain where the critical code (that contributes to overall performance optimization), also called the “hot spot”, actually lies. This takes some detective work, and you should do it, to the extent it is possible. But maybe your team is still building your system, and it will be three months until you’re able to do a real, solid measurement that confirms that Feature X is in dire need of optimization, at which point it may be too late, because Feature X is necessary in order to complete other parts of the project. In the meantime it’s uncertain, and you’re essentially making a bet, one way or the other. So what’s your appetite for risk? What’s your project manager’s appetite for risk? If you identify an area of code that is possibly but not necessarily critical to optimize, bring it up with your team and treat it accordingly. And gather as much evidence as you can, since that can help reduce the uncertainty.
Again: it’s speculative optimization. On the one hand, don’t fall prey to a fool’s errand in a gold rush; some will succeed but many will fail. On the other hand, there is gold in them thar hills, you just have to do your homework to make the best out of opportunity and luck.
But I don’t think that really conflicts with Knuth’s advice. After all, he says it “is often a mistake” which doesn’t mean it’s always a mistake.
Too Late for an Overture, but Let’s Try Anyway (TL;DR #2)
Okay, you’re already well into this article, so presumably you don’t mind my occasional blathering about Stack Overflow and imaginary kittens. But let’s take a bird’s-eye view of the situation and figure out where we’re going.
The conventional wisdom of software development, to paraphrase Knuth, is that worthwhile opportunities for optimization of software are confined to only a few pockets of critical code (the apocryphal 3%), and are much easier to determine by measurement than by intuition. Avoid Premature Optimization, which is the Root of All Evil, because that’s what the last guy said, and he seems to be doing okay, so why shouldn’t you follow his advice?
Here’s the thing. I’ve got a particular idea in mind. And so far in this article I have been creeping stealthily around the edges, but now it’s time to pull back the curtain:
Beware of an overdependence on profiling tools. Software optimization is no different than any other type of applied optimization. When we automate it, or oversimplify it, or turn it into a set of predetermined rules, we shirk our responsibility as engineers, doing so at our own peril.
Huh?
Knuth has not only given us a snazzy sound bite (Premature optimization is the root of all evil!) but has vouched for the superiority of automated profiling tools over fuzzy engineering judgment. And in many cases, choosing to optimize execution time based on the output of a profiler is a good strategy. But how could it not be?
Let me count the ways:
- Risk reduction may require some optimization work before it is possible to measure execution time — we talked about this already
- Strategic optimization and tactical optimization should be handled differently
- Critical code may be more abundant in some systems
- Optimization doesn’t always refer to execution time
- Not everything can be measured with certainty
- Measurements for optimization may not be measuring the right thing
- Measurements can tell you how fast code runs now, but not necessarily how fast it could run or how easy it is to make it run faster
- Criteria for measurement may change with time
- Criteria for measurement may change from one situation to another
- The effects of an optimization effort may increase (or decrease) even after that effort is complete
- Small gains may still have high value in some systems
- Imperfect attempts at optimization still have value
- It’s still possible to make incorrect conclusions from quantitative measurements
- Information overload, even if it is good information, can blind us from the best conclusions
- Abundance of computing resources makes us assign low value to many types of optimization
Some of these you will read these and shake your head with a groan, saying that these are edge cases, pathological situations, like that trick question about the locked room with the broken window and the two dead bodies on the floor surrounded by water and broken glass. My premise is that pathological situations are a lot more frequent than we care to admit.
So let’s explore some of them.
Sun Tzu Returns, This Time Without a Dishwasher
Many of the “premature optimization” questions on Stack Overflow are tactical in nature. For example:
- Should I preallocate a list in Python?
- Does using
instanceofin Java pose a performance hit? - Is it faster to cast something and let it throw an exception than calling
instanceofto check before casting? - What’s most efficient in Java: creating a new instance or changing a value in an existing one?
- In C++, is
>faster than==?
They’re tactical because they’re very concrete questions dealing with localized implementation details, and have very little to do with the overall software architecture. Here’s where Knuth’s advice really rings true; if you have two choices A or B for implementing some feature, and that choice has very little to do with the rest of the program, then you can almost always leave this choice until later, when you are evaluating the performance of your software and can optimize details when they appear to be necessary.
The main problem I have with overuse of the “premature optimization” quote, as a response to programming questions, is that most people on Stack Overflow seem to view such questions as instances of a tactical problem that must be solved in order to complete a project. Do you ever see a combat scene in television or the movies, where one person hesitates to make a decision: Should I hit them in the neck or the stomach? Should I shoot them in the head or the shoulder? Probably not. Aside from the fact that it would ruin the pace of the action, if they did hesitate, they would almost certainly lose, because the other person isn’t going to hesitate. (The truel at the end of The Good, the Bad, and the Ugly is a rare exception.) When you’re in the middle of a fight, it’s too late to decide on tactics; you either know what you’re going to do, or you don’t.
There’s only one reason I can think of to stop and spend lots of time considering tactical decisions, which is training and practice, and which I’ll bring up again later.
Strategic optimization, on the other hand, is extremely important, and decisions at a strategic or architectural level may have wide-ranging consequences. Dismissing a strategic decision, as an example of premature optimization at a tactical level, is a grave mistake, and is probably the biggest criticism I have with Knuth’s quote.
From here onward, I’m going to assume that all decisions are strategic in nature unless I mention otherwise. The tactical ones are easy to deal with: if they’re a localized design decision, then Knuth is absolutely right, and you shouldn’t optimize — at least consciously — until you’re measuring performance and can identify the bottlenecks. There’s a comment by Mike Montagne, on a blog post by Charles Cook, that argues against what he sees as Knuth’s philosophy, and ironically I agree with it most of it:
WHEN you are concerned AT ALL with these “small inefficiencies,” all the necessary patterns soon become obvious. They aren’t difficult matters; nor are they cumbersome or inexpeditious. On the contrary, when your fingers start typing… you’re automatically headed that direction because previous work (the right way) abstracted the associated pattern into a pattern of work which eliminates from the start, all the “small inefficiencies.”
But those patterns, and those patterns of working, also reduce the larger challenges to doing a job well/right, the first time. If you know the technologies you’re working with, you know there’s a right way — and that’s what you are doing. There isn’t even a question of “forgetting” (or handling) “the small inefficiencies.” Skill means seeing the way from the start — not as an impenetrable or inexpedient difficulty, but as eliminated difficulty.
To say on the contrary that there are any “small inefficiencies” to dispense with, is to cast away principle. Principle is what you have to return to, if you’re ever going to do the job right. And principle is what you have to observe before you start therefore, if you’re going to get the job done most efficiently — and if what you turn out first is even really going to take us where we really need to go.
A good coder sees the way, not as small inefficiencies to be dispensed with, but as routine patterns to be handled in ideal ways, practiced by constant discipline – which always, always, always seeks the optimal way. Getting there always is what gives you the skill to turn out optimal end product from the beginning. Not in more time, but in less.
Tactical optimization: routine patterns to be handled in ideal ways, practiced by constant discipline — if you’re a veteran programmer, then just do it (and do it right), but if you are a beginner, just do it, and if it’s not a very good choice, your non-optimality in a localized design decision will show up in profiling work or a code review.
Is It Always 3%?
One question to ask: is “critical code” for tactical optimization only about 3%?
Knuth assumes that a small portion of code stands out as a hot spot — namely, if you were to profile the time of execution of your program, you would probably see something like a Pareto distribution where a very small percentage of the code contributes to a large percentage of execution time, and a very large percentage of the code doesn’t contribute much at all.
Whether this is true or not depends on the type of software. Numerical software does tend to have some inner loop that executes often, and in that case, if reducing execution time is an important priority, then, yeah, you need to find it and do what you can to make it faster. Unrelated code that executes infrequently has low potential for any impact on the overall execution time. You can bet that Google spends time optimizing their code that executes PageRank, and Facebook spends time optimizing their graph-algorithm code, and MathWorks spends time optimizing their matrix, solver, and simulation algorithms. The same holds true with software that deals with data transfer, where throughput and latency are vital, and the parts of the program that process data are are obvious candidates for hot-spot code. (Real-time signal processing falls into both of these categories!)
But other types of software can be different.
For example, software with lots of branches and error-handling code and special cases might have less than 1% hot-spot code; it could be 10 lines out of a million that impact certain slow calculations. And maybe you won’t find it unless certain odd conditions are true. So a profiler won’t help unless the conditions are set up accordingly.
At the other extreme, I work on motor control software in embedded systems, where we typically have an interrupt service routine that executes at a regular rate, typically in the 50 - 200 microsecond range. That’s thousands of times per second, and it can’t be late, without causing a disturbance to the motor. In addition, the code that runs is very linear in nature; there aren’t a lot of loops or branches, just a bunch of processing steps one after the other. Remember this chart from the Amdahl’s Law article, where we gave an example of a bunch of tasks being sped up?

The hot-spot code in our motor control ISR (which might be 40% of the entire codebase) typically looks like this. If I’m on an optimization hunt, usually I have to look everywhere, and make slight improvements where feasible. Yeah, there might be only a few areas where I find room for improvement without a huge implementation cost, but the critical code in our situation is much larger than 3%.
And yet, aside from this number being different from 3%, the point is that you should take actual measurements of execution time! It’s much more productive to target your efforts on specific areas of code, based on real evidence, rather than speculation.
As a side note: power supply circuit design is similar to the motor control ISR situation; to increase energy efficiency from, say, 95% to 97% takes slight improvements in several areas, including the transistors, the gate drive circuitry, the magnetics, the capacitors, and so on. It’s really hard to make much of difference in efficiency if you only attack one aspect of the system. This is actually fairly common in engineering, where the performance metric depends on many components all working together, so you have to improve several of them simultaneously if you want an overall improvement. It’s rare to find systems where one component determines the overall performance. Somehow in software we end up with (or at least we think we end up with) execution time bottlenecks that depend heavily on only a few critical areas of code.
A Riddle: When Is the Fastest-Executing Code Not the Most Optimized Performance?
Sometimes optimization doesn’t mean execution speed. You need to make sure you understand your project’s priorities, which could be
- time to market
- feature set
- ease of use
- look and feel
- reliability/robustness/accuracy
- other aspects of performance besides speed
This last aspect needs some explanation. In many fields there are other metrics for performance besides execution speed. In motor control, for example, performance can be judged by torque smoothness or disturbance rejection, so if there is a sudden transient that slows down an electric lawnmower, it recovers quickly. Noise-canceling headphones can be judged by their attenuation at various frequencies. Digital photography can be judged by many aspects of image quality.
In any case, if you are trying to optimize software execution speed, but there are other aspects of the project which have much higher priority, then you are wasting effort that could be better spent on other types of improvements.
Another Riddle: When Is the Value of Code Optimization Something Other than Optimized Code?
One of my pet peeves with Stack Overflow is that sometimes the goal of a question is not necessarily just to receive an answer. Engineering has gotten more and more complex over the past few decades, which means it’s more and more difficult for one person to learn all of the skills needed to complete a project. So unless you just happen to have someone on your staff who has experience in the problem at hand, there can be a lot of stumbling blocks, and it’s very unlikely that you will get past them efficiently. I call this the AB Problem. Somehow, management expects software development efforts to get from Point A to Point B in an acceptable timeframe, and each step of the way should be scheduled so that the project can be done on time, and engineering work can start on the next project. Just like an airline flight. If you remember Casablanca and Raiders of the Lost Ark, they each showed a travel montage with a line unfolding across a map, as our heroes traveled from Paris to Marseille to Oran to Casablanca, or from San Francisco to Honolulu to Manila to Kathmandu. That’s what you want project progress to look like:

Or, at worst, like this:

But real projects tend to careen in all sorts of directions, especially when engineering staff is doing something where they’re not quite sure how to get from Point A to Point B, and you end up with this:
or this:
or this:

or sometimes this:
or sometimes they don’t get to Point B at all, maybe they end up at Point C, or the project is canceled, or the company goes bankrupt. You don’t want that. It’s really important to have at least a general idea of the right way to get to Point B.
With projects that have large uncertainty, there is value in learning. It is better to meander a little bit, understand when you’re getting off track, and make quick corrections, than it is to zoom full-bore in a straight line in the wrong direction. So the occasional brief experiment with speculative strategic optimization, even if you know that it isn’t contributing to the performance of hot-spot code, isn’t a bad thing — as long as you don’t forget that it is a side project. And be sure to archive that work properly: make it easy to find later, and add whatever notes make it clear what you did and what effect it had. You never know when you might reuse this work again.
For tactical optimizations, there’s value in learning as well. Training and practice can help here, even if all it does is to help you stop worrying about the small efficiencies and leave your focus for the strategic ones.
As far as Stack Overflow goes: I wish people who answer questions realized more that sometimes questions are hypothetical, and they’re asked to help learn from the experience of others, and to avoid spinning around in circles.
How to Play Pin the Tail on the Donkey When The Rules Keep Changing
Speaking of spinning around in circles, you’ve probably played this game before:

(Photo by “Bell and Jeff” originally posted to Flickr as Pin the Tail, CC BY 2.0)
That’s right, it’s Pin the Tail on the Donkey, the game of asinine optimization. Very straightforward: you win if you stick a paper tail closer to the goal than anyone else. The blindfold and dizziness are just minor obstacles. But what happens if the donkey gets moved or turned upside-down in the middle of the game? Or if the game is changed to become Pin the Hoof on the Donkey?
Let’s say it’s November 1998, and you’re creating this awesome new web browser called ScapeNet that works with the latest blazing-speed 56K dial-up modems. Your goal is to make your software better than anything else, so you can sell it for \$19.99 to millions of potential customers and make lots of money. You know about Premature optimization is the root of all evil, so you dutifuly profile your application and figure out where the hot-spots are, based on PCs with the latest Pentium II processors and 56K dial-up connections. Then you and a bunch of your fraternity buddies figure out what you can do in a couple of weeks to get ScapeNet out on the market before the dot-com bubble bursts. Your renderer and your implementation of Javascript are both really fast. Great! Optimization problem solved: minimum amount of work to get acceptable performance.
Now fast-forward five years: it’s 2003, DSL and cable modems have started to take off, and ScapeNet doesn’t work so well anymore. You and your frat buddies are all married with young kids, and nobody wants to revisit some of the inner crufty code that worked fine on 56K dialup but not so well on broadband high-speed Internet access. Sllllowwwwww.
The rules have changed. Should you have spent more time in 1998 optimizing your software architecture to handle higher data rates? Maybe, maybe not.
One slight problem with optimization in the mathematical sense, is that it produces fixed outputs only for fixed inputs. So when I make the best decision possible, based on the best available data, for where to apply my engineering efforts, but that data changes over time, then my decisions can be out of date and wrong. This re-introduces risk into the equation. You may know what the best decision is right now for optimizing your software, but in six months or a year, the game may have changed, and if you really want to make the right decisions, you have to revisit your assumptions as the facts change.
Here’s another design example, this time in the area of AC adapters, also known as “wall warts”:

From left to right, these are:
- Rayovac power supply for camera battery charger: 12V 0.5A (6W)
- BlackBerry charger (don’t ask me where I got this; I’ve never owned a BlackBerry): 5V 0.7A (3.5W)
- Apple iPhone charger: 5V 1A (5W)
Notice they’re all around the same general power level, but the size has gotten quite a bit smaller over the years. The Rayovac adapter uses a 60Hz transformer, with a rectifier and voltage regulator. I know this without even opening up the case, because it’s much heavier. This type of AC adapter has been around for years, and for a long time was the optimal solution for this kind of application, because it’s simple and cheap.
The other two chargers are smaller and lighter, and use high-frequency switched-mode power supplies to reduce the size of the magnetics needed in the power supply. (In case you’re interested, this is true because magnetic components are rated approximately for their stored energy capability, and if you increase the frequency at which you transfer power, the amount of power you can handle for a given size increases. Alternatively, to handle the same power, you need a smaller volume of magnetics.) This technology has been around for several decades, but it hasn’t been cost-effective to use for small AC adapters until the mid-1990s, when companies like Power Integrations introduced small and inexpensive control electronics to handle low-power AC/DC converters. Then the magnetics got cheaper and more readily available, because all of a sudden there was this market for low-power switched-mode converters, and the economies of scale kicked in.
The rules changed somewhere in the 1998-2005 range: customers could be provided with lightweight AC adapters for reasonable costs, which wasn’t the case a few years earlier.
In July 2008, Apple introduced the iPhone 3G, with its distinctive “cube” charger that was much smaller than other adapters. This was the first time that an AC adapter of this power level was really optimized for size, and it’s not an easy feat: part of the problem with a small adapter is that there are minimum required distances (creepage and clearance) between any conductors that carry AC mains voltage, and any conductors that connect to the output terminals. It’s a real feat of engineering, something that wouldn’t have made much business sense to commodity AC adapter manufacturers, but for Apple the idea of premium high-end design was part of their business philosophy, and in the intervening decade other companies on the commodity end have come out with small AC adapters as well.
Let’s just revisit this for a second:
- In 1997, bulky 60Hz transformers were the normal, cost-optimal solution for AC/DC converters in the 3-10W range
- In 2017, high-frequency switchers are the normal, cost-optimal solution. Ultra-compact switchers have enough appeal, and are well-established enough that consumers are willing to pay slightly more to support a market for them.
Again – the rules changed! Optimization is not a one-time task, but rather a reoccurring responsibility in a changing market.
Awareness, Land of a Thousand Choices, and Information Overload
Let’s come back to a point I made earlier:
As a side note: power supply circuit design is similar to the motor control ISR situation; to increase energy efficiency from, say, 95% to 97% takes slight improvements in several areas, including the transistors, the gate drive circuitry, the magnetics, the capacitors, and so on. It’s really hard to make much of difference in efficiency if you only attack one aspect of the system. This is actually fairly common in engineering, where the performance metric depends on many components all working together, so you have to improve several of them simultaneously if you want an overall improvement. It’s rare to find systems where one component determines the overall performance. Somehow in software we end up with (or at least we think we end up with) execution time bottlenecks that depend heavily on only a few critical areas of code.
I’m an electrical engineer, and sometimes I work on circuit design as well as embedded firmware. Circuit design is a whole different problem domain from software, and although I consider myself a good specialist in certain areas of it, I’m not the guy who’s going to design your next high-volume low-cost lightweight high-efficiency battery charger. That’s difficult — at least for me. But it’s a different kind of difficulty from software engineering.
Circuit design starts kind of the same as software design: you make sure you understand your requirements, you come up with an architecture, identify risks that need to be addressed, start implementing various functions, and so on. But there’s no operating system or libraries; instead, you’re putting different components on a circuit board: resistors, capacitors, magnetics, integrated circuits, buttons, switches, and so on. A typical circuit board might have anywhere from 10 - 500 components on it. More than 100 components is fairly rare — at least for me — and it’s hard for me to get my head wrapped around such a design. In almost all cases, each of the components does one thing, and a good circuit designer would make it clear what the purpose of each component is, not by the design itself, but by annotations on the design schematic (“R33 to limit slew rate on voltage input”), appropriate grouping of related components on the schematic in close visual proximity, and a written description of the design. The complexity doesn’t tend to be that high.
Optimization in circuit design plays a much larger and visible role than in software design. It would be possible to dismiss optimization as “premature” and just create a design that fulfills the required functions, without worrying too much about things like power consumption, power dissipation, circuit board size, and cost. In fact, prototypes are often created this way. Make it work first, then optimize as necessary. But some level of optimization usually has to take place, and it may vary from just methodically looking through the schematic to see which components can be replaced, one by one, with less-expensive alternatives, to packaging optimization where a more holistic approach is required and more of the work affects the circuit layout. Optimization is rarely easy (otherwise it would have been done in the original circuit design) but it is something that a circuit designer usually keeps in mind with proper perspective — each optimization has tradeoffs and should prove demonstrable gain.
The difference in software optimization has to do with the complexity. The circuit designer usually deals with a much simpler set of components, and it’s almost always possible for one person to understand the design in its entirety. So keeping a mental list of possible approaches for optimization isn’t too bad. I could review most circuit designs completely in the matter of a few hours, to look at things like power dissipation or cost, and identify some potential avenues for improvement all by myself. Software, on the other hand, can include thousands or even millions of lines of code, which presents a real problem, because there are just too many choices for one person to see them all.
So what do we do? Run a profiler, and hope there is a pattern where some bottleneck presents itself as the execution hog. Slay it, and all will live happily ever after. But what if we don’t see such a pattern? Then we’re left with our thousands or millions of lines of code, and somehow we have to look for the clues to find an opportunity to reduce execution time. Can we, mere humans, learn to focus on things that a computer cannot?
Malcolm Gladwell brings this idea up in his book Blink, which explores the role of the subconscious mind in rapid decision-making, something that psychologists Nalini Ambady and Robert Rosenthal called thin-slicing. Here is Gladwell talking about Dr. John Gottman’s research on interaction between married couples, through analysis of videotaped conversations:
Have you ever tried to keep track of twenty different emotions simultaneously? Now, granted, I’m not a marriage counselor. But that same tape has been given to almost two hundred marital therapists, marital researchers, pastoral counselors, and graduate students in clinical psychology, as well as newlyweds, people who were recently divorced, and people who have been happily married for a long time — in other words, almost two hundred people who know a good deal more about marriage than I do — and none of them was any better than I was. The group as a whole guessed right 53.8 percent of the time, which is just above chance. The fact that there was a pattern didn’t much matter. There were so many other things going on so quickly in those three minutes that we couldn’t find the pattern.
Gottman, however, doesn’t have this problem. He’s gotten so good at thin-slicing marriages that he says he can be in a restaurant and eavesdrop on the couple one table over and get a pretty good sense of whether they need to start thinking about hiring lawyers and dividing up custody of the children. How does he do it? He has figured out that he doesn’t need to pay attention to everything that happens. I was overwhelmed by the task of counting negativity, because everywhere I looked, I saw negative emotions. Gottman is far more selective. He has found that he can find out much of what he needs to know just by focusing on what he calls the Four Horsemen: defensiveness, stonewalling, criticism, and contempt. Even within the Four Horsemen, in fact, there is one emotion that he considers the most important of all: contempt. If Gottman observes one or both partners in a marriage showing contempt toward the other, he considers it the single most important sign that the marriage is in trouble.
In essence, a good portion of Blink is about this phenomenon, that the best experts can tune into key parts of a problem to analyze — even if they may not know how their brain goes about doing it.
So if I’m analyzing code trying to make it more faster, and there’s some big fat bottleneck in it, then a profiler can probably help me find that. Great, anyone can use the profiler. But once I’ve gotten rid of the big fat bottlenecks, what’s left? It may not be so easy to find ways to improve on execution efficiency at that point, and further improvements may require a mix of intuition, insight, and luck — all of which are easier and more natural for someone who’s been practicing improving program efficiency, whether or not it was useful practice.
I look at profiling as a tool. It can help me see very clearly how long different parts of the program take to execute in one particular environment, and that may give me some ideas — typically at a tactical level, sometimes at a strategic level — for how to improve the overall execution time, but it will not tell me much about which sections of the code are the best candidates for that improvement. Perhaps two sections of code, A and B, are always called at the same rate, and they each take about 14 microseconds to execute on my PC, before any optimization. I have no idea whether the best I can do for each of them is 13.5 microseconds, or 10 microseconds, or 2 microseconds, or 130 nanoseconds. It could be that A has a theoretical minimum execution time of 10 microseconds and B has a theoretical minimum of 3.7 microseconds — in which case, at first glance, it would be better to optimize section B because it has the higher theoretical gain in execution speed. But I have no idea how much work it will take to get the execution time down to a near-optimal level. Maybe A and B each can be optimized to 1.6 microseconds but B is the much simpler optimization effort. These are things that a profiler cannot tell you, and you’re left to rely on your intuition and experience.
Moreover, if I always start with profiler data, I may be overwhelmed with information, and biased towards particular conclusions based on the numbers. In the afterword of the 2007 edition of Blink, Gladwell recounts this study:
About a year after Blink was published, Science — one of the most prestigious academic journals in the world — published the results of an experiment conducted by the psychologist Ap Dijksterhuis and a number of his colleagues at the University of Amsterdam. Dijksterhuis drew up a description of four hypothetical cars and gave the performance of each of them in four different categories. So, for example, car number one was described as having good mileage, good handling, a large trunk, and a poor sound system, while car number two was described as having good mileage and a large trunk but was old and handled poorly. Of the four, one was clearly the best. The question was: How often would consumers, asked to choose among the four alternatives, pick the right car? Dijksterhuis gave the test to eighty volunteers, flashing the car’s characteristics on a screen in front of them. Each test taker was given four minutes to puzzle over the problem and then was asked for an answer. Well over half of the test takers chose the right car.
Then he had another group of people take the same test, except that this time, after giving them all of the information, he distracted them by having them do anagrams. After a four-minute interval, he posed to them the same question, seemingly out of the blue: Which car do you want? Well under half of the test takers chose the right car. In other words, if you have to make a decision, you’ve got to take your time and think about it first. Otherwise, you’ll make the wrong choice. Right? Not quite. Dijksterhuis went back and redid his experiment, only this time he classified the cars in twelve different categories. What was once a simple choice was now a complicated one. And what happened? The people given four minutes to deliberate got the right answer a mere 20 percent of the time. Those who were distracted by doing anagrams — those who were forced to make an unconscious, spontaneous gut decision — chose the best car 60 percent of the time.
We don’t know how the brain works to make good decisions, but its ability can be impaired by having too much information, or being primed by what it has considered immediately before a decision.
One thing that’s really hard to do when faced with profiling information is focus on strategic decisions. It’s easy to look at those numbers and have ideas for tactical optimization, but strategic optimization takes some careful analysis: how do I take specific data and understand general trends, such as correlation between performance and particular input variables, or order of growth of execution time with problem size.
With optimization of software, decision making is needed to choose from among billions or trillions of possible avenues of exploration, whether it’s guided by profiling information or purely by experience and intuition. Regardless of the method of decision, though, creating a prototype and using profiling tools before and after a software change will give us an objective comparison of whether an optimization is valuable enough to pursue to its conclusion.
Or will it?
When is a Microsecond Not Always a Microsecond?
I already talked about how optimization criteria can change over time: the best approach to writing a particular type of software can change in just a few years, as computing power and our use of it both increase. Today’s slow software might seem very responsive five years from now.
But the passage of time isn’t the only factor that can change the way we value execution speed. We have different kinds of systems out in the world crunching numbers and transferring data, from slow 8-bit microcontrollers to supercomputers, and optimizing these systems can pose a challenge just figuring out how to tell when the results are adequate. It may be very easy to measure performance objectively: run some experiments, and see that your system processes \( X \) amount of data in \( Y \) seconds when used in some computing environment \( Z \). The question to ask, though, is how do we compute the value of this performance, \( V(X,Y,Z) \)? We know the system is better if the time decreases, but how do I know when it’s good enough? And what type of environment should I test it on?
Dan Luu writes about the use of the Internet in areas with slow transmission speeds:
More recently, I was reminded of how poorly the web works for people on slow connections when I tried to read a joelonsoftware post while using a flaky mobile connection. The HTML loaded but either one of the five CSS requests or one of the thirteen javascript requests timed out, leaving me with a broken page. Instead of seeing the article, I saw three entire pages of sidebar, menu, and ads before getting to the title because the page required some kind of layout modification to display reasonably. Pages are often designed so that they’re hard or impossible to read if some dependency fails to load. On a slow connection, it’s quite common for at least one depedency to fail. After refreshing the page twice, the page loaded as it was supposed to and I was able to read the blog post, a fairly compelling post on eliminating dependencies.
Complaining that people don’t care about performance like they used to and that we’re letting bloat slow things down for no good reason is “old man yells at cloud” territory; I probably sound like that dude who complains that his word processor, which used to take 1MB of RAM, takes 1GB of RAM. Sure, that could be trimmed down, but there’s a real cost to spending time doing optimization and even a \$300 laptop comes with 2GB of RAM, so why bother? But it’s not quite the same situation — it’s not just nerds like me who care about web performance. In the U.S., AOL alone had over 2 million dialup users in 2015. Outside of the U.S., there are even more people with slow connections.
He then goes on to analyze a number of websites (mostly programming blogs, along with reddit and google.com and amazon.com) using https://www.webpagetest.org and the results are pretty dismal:
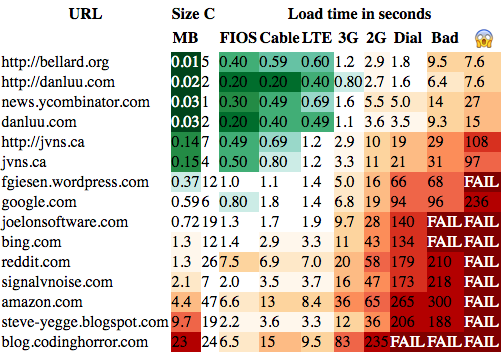
Just for kicks, I decided to try this sort of thing myself, and see how much data gets transfered in the case of MSDN documentation. Here’s the page for COM’s IUnknown::QueryInterface, which you may remember from my “Garden Rakes” article, profiled with client-side caching disabled, using Google Chrome’s Developer Tools:
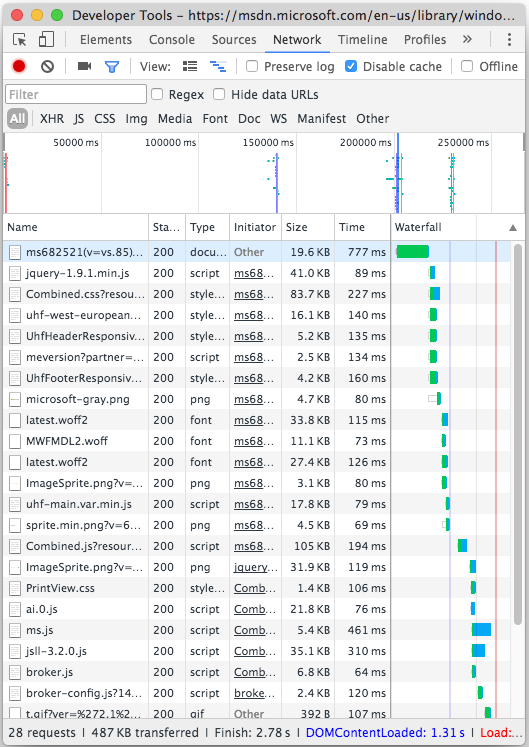
On my computer we’re down to about 1.3 seconds to get to the DOMContentLoaded event — and I’ve got a reasonably fast computer with a reasonably fast connection (≈ 10 megabit/second) to the Internet. But this takes 19.6K of HTML, 61.3K of Javascript, 109.2K of CSS files, 72.3K of font files = 262.4K (+ another 225K of stuff downloaded after DOMContentLoaded). Granted, it’s all sent compressed with gzip-encoding — for example, the big 85K CSS file is gzipped down to 13.5K — but then you add HTML headers and TCP/IP overhead, and over 56Kbit dialup with some overhead for PPP, it would take a while. The webpagetest site says this page would take over 30 seconds to get to DOMContentLoaded over a 56Kbit link; the first 19.6K HTML alone takes between 7.9 and 11.8 seconds to receive, in the three test trials I ran.
I cannot imagine bouncing back and forth between MSDN pages on dialup. It’s bad enough to use it on a fast Internet connection, and I’d take a slow initial download if they would just redesign their damn site so that you had the option to view related pages all at once in one large HTML page, rather than getting lost in a maze of clicks to load page after page.
With caching re-enabled, on my computer the amount of data transfered gets reduced to just the initial 19.6K of HTML (everything else cached client-side), although for some reason the server took longer to respond, and DOMContentLoaded took 1.6 seconds:
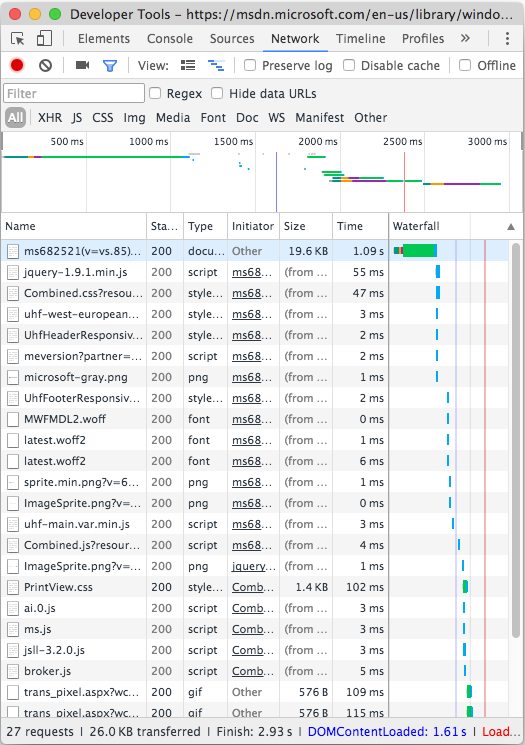
I can’t figure out how to configure webpagetest to show me the results with caching enabled, but I’d assume it’s just the time needed to download that initial 19.6K of HTML, or 7.9 - 11.8 seconds.
Do you think people learning software development in remote rural areas of the world enjoy using the MSDN website? And if we really wanted to make information more available to the billions of people on this planet, shouldn’t we try to do a better job with our WWW servers, so that at least they get something downloaded quickly? A page of plaintext in 5 seconds is better than a page of glitzy images and AJAX that takes 5 minutes to load.
So what’s the typical requirement for judging web performance? Is it with a 10 megabit/second DSL or cable modem connection? Or a 56K dialup modem? Or some remote connection that averages 16 kilobits/second with frequent errors and timeouts? It depends on what market is being considered. Presumably if you’re a manufacturer of some bleeding-edge \$300 Wi-Fi gadget, you’re not trying to market to billions of people on the planet; you’re aiming for affluent customers who have access to high-speed Internet. But maybe you run a travel website for online lodging transactions, and many of your customers live in areas with poor Internet access, or are visiting such areas. In that case, it’s not such a good idea to assume a fast Internet connection.
(A side note: this little exercise has brought back some personal memories. My very first job back in the summer of 1992 was working with my university’s Information Systems department on software used for campus information retrieval — in particular, porting it from Unix to Windows 3.1. It was a custom system and protocol encoded in a very terse format, kind of like Gopher but more obscure. In summer 1993 I worked for the same department, and I remember one day this guy came in to demonstrate some software for hyperlinked information retrieval over the network. He showed it on one of our Unix boxes in the test lab; it was interesting, and it had some basic text and formatting features. He showed us a snapshot of the data transferred and I remember we turned up our noses at it in disgust because it was text-based, not even an attempt at trying to keep the bandwidth down. It had all this stuff in it like <html><head><title>Hypertext Transfer Protocol</title><body>. I don’t know if that guy was Tim Berners-Lee, or some other guy who had jumped on the HTML bandwagon very early, but in any case I missed the boat on HTML and Internet mania in my college years. My initial reaction — Ewwww, it’s text-based! — is something I try to keep in mind, as an amusing fallacy, when the topic of premature optimization comes up; the overhead of HTML tags really doesn’t add a whole lot when you consider that data compression can reduce the overhead of human-readable English, and it’s possible to create HTML files with very high information content and not much formatting. In the area of small embedded systems, however, I avoid sending human-readable content over UART; as long as the information content has a constrained structure — for example, the same 12 integer values of data transmitted once per millisecond — binary makes much more sense. The debate over human-readable vs. binary rages on… who knows if EXI will ever take off in certain problem domains.)
At any rate, Dan Luu’s article contains one more little surprise at the end:
When I was at Google, someone told me a story about a time that “they” completed a big optimization push only to find that measured page load times increased. When they dug into the data, they found that the reason load times had increased was that they got a lot more traffic from Africa after doing the optimizations. The team’s product went from being unusable for people with slow connections to usable, which caused so many users with slow connections to start using the product that load times actually increased.
The mere act of making an optimization caused the rules to change!
One final anecdote before we move on to another section: I work in a semiconductor company that makes microcontrollers, and every so often I get involved in defining new products. Recently the question came up of how much memory to put into a particular part. The problem was in weighing the cost of additional memory (more memory = larger die area = larger cost to produce) vs. attractiveness to the customer of having more memory for software development. Memory in this industry is measured in kilobytes, not megabytes or gigabytes. Embedded microcontrollers are a whole different beast from your PC or the processor in your mobile phone. Choose too much memory, and the cost goes up by a little bit — maybe just a penny, but high-volume markets may be less interested and you’ll lose business to the competition. Choose too little memory, and you’ve just made it impossible for certain customers to use your part. Or maybe they can use the part in production, but during development they need to add new features, which won’t fit, so they can’t use it, or they have to work a lot harder during development to get around the lack of memory. It is very difficult to estimate the net value to the company and make an optimum decision. We ended up trying to err on the high side.
The key ideas not to forget here are
- Criteria for measurement may change drastically from one situation to another
- As technology innovators, our own abundance of computing resources sometimes makes us assume low value to many types of optimization, even when that assumption may not always be valid.
Uncertainty and Sensitivity
Let’s go back to one of our mathematical examples, where the goal was to choose the value of \( x \) that would maximize this function \( f(x) \):
$$\begin{align} f(x) &= \frac{a}{1+(x+1)^2} - \frac{a}{1+(x-1)^2} + \frac{b}{1+x^2} \cr a &= \zeta - 0.5 \cr b &= \frac{1}{6}\zeta(1 - \zeta) \end{align}$$
With precise knowledge, we can figure out exactly what value \( x \) is optimum.
Unfortunately that’s rarely the case. Maybe I don’t know exactly what \( \zeta \) is, all I know is that it’s likely to be between 0.45 and 0.65. Or maybe my equations for \( a \) and \( b \) are estimates, and they might be wrong. In this case, I need to deal with uncertainty in the problem parameters, and one way to look at this is the sensitivity of my optimization to these parameters.
In this particular case, the optimum value of \( x \) is very sensitive to \( \zeta \) when \( \zeta \) is near 0.5. Whereas if \( \zeta \) is less than 0.4 or greater than 0.6, there’s very little change in the optimum value of \( x \).
(Mathematically, if \( x_{opt}=g(\zeta) \), we’re talking about the partial derivative \( \frac{\partial g}{\partial\zeta} \)… and strictly speaking, sensitivity is usually expressed in fractional terms, so we might be interested in
$$S = \frac{\zeta}{g(\zeta)}\cdot \frac{\partial g}{\partial \zeta} \approx \frac{\frac{\Delta g(\zeta)}{g(\zeta)}}{\frac{\Delta \zeta}{\zeta}}$$
which is the fractional change in \( x \) with respect to the fractional change in \( \zeta \).)
One of the important points for strategic optimizations is to know which factors your system is or is not sensitive to. For example, if I’m processing audio, as long as my system is fast enough to keep up with incoming data, I don’t really care about the CPU rate. For CD-quality sound this is 44100 samples per second. Maybe I can’t do this with a Commodore 64 or pre-Pentium PCs, but simple audio processing has been within the realm of modern PCs and smartphones, and which processor I use doesn’t matter as long as it’s fast enough. Latency, on the other hand, is important, and it means that I have to buffer up enough audio in my input and output devices (which are outside of the main CPU), so that for any interruptions where the audio processing gets delayed, the data keeps being delivered smoothly. As a listener to the radio, I don’t really care if my radio is delayed by a second or even 10 seconds as long as it sounds the same. For real-time systems like video gaming or phone conversations or professional music recording, however, even small delays are noticeable, and there is very high value in keeping latency to an absolute minimum. So the way audio software is architected may be completely different between prerecorded and real-time audio applications.
Not everything can be measured with certainty (even profilers have some variability from one run to the next), so understanding the effect of uncertainty is important, and conservative or worst-case analysis might be appropriate. In another article on engineering design margin I talked about risk aversion and how the expected value of an uncertain quantity is not always the best estimate to use.
Let’s say we had a similar mathematical situation as before, but with a slightly different equation:
def f(x,zeta):
a = (zeta-0.5)
b = (zeta-zeta**2)/6.0
return a/(1+(x+1)**2) - a/(1+(x-1)**2) + b/(0.25+0.1*x**2) - b/(0.2+x**4)
zeta_list = np.arange(0,1.01,0.1)
for zeta in zeta_list:
plt.plot(x,f(x,zeta));
for x1 in [-1.05,1.05]:
plt.text(x1,f(x1,zeta),'%.1f' % zeta,
fontsize=10,
verticalalignment='bottom',
horizontalalignment='center')
plt.title('$f(x)$ as parameter $\\zeta$ varies');
plt.grid('on')
Perhaps all I know is that \( \zeta \) is equally likely to be any value between 0 and 1; if this is the case then I can use numerical analysis to compute an approximate expected value of \( f(x) \), which we’ll graph along with the worst-case value of \( f(x) \) and the 5th percentile:
zeta_list = np.arange(0,1.001,0.01)
x_list = np.arange(-3,3,0.001)
x,zeta = np.meshgrid(x_list,zeta_list)
y = f(x,zeta)
y_expected = np.mean(y,axis=0)
y_min = np.min(y,axis=0)
y_q05 = np.percentile(y,5.0,axis=0)
fig=plt.figure(figsize=(8,5))
ax=fig.add_subplot(1,1,1)
ax.plot(x_list,y_expected,label='E[f(x)]')
ax.plot(x_list,y_min,label='min[f(x)]')
ax.plot(x_list,y_q05,label='5%')
ax.set_xticks(np.arange(-3,3.01,0.5))
ax.grid('on')
ax.legend(loc='best', fontsize=10, labelspacing=0)
ax.set_title('Expected value $E[f(x,\\zeta)]$ and worst-case for uniformly-distributed $\zeta$')
i_opt = np.argmax(y_expected)
print "Best choice of x to maximize E[f(x,zeta)]:"
print "x=", x_list[i_opt]
print "E[f(x,zeta)]=%.3f" % y_expected[i_opt]Best choice of x to maximize E[f(x,zeta)]: x= -1.155 E[f(x,zeta)]=0.058
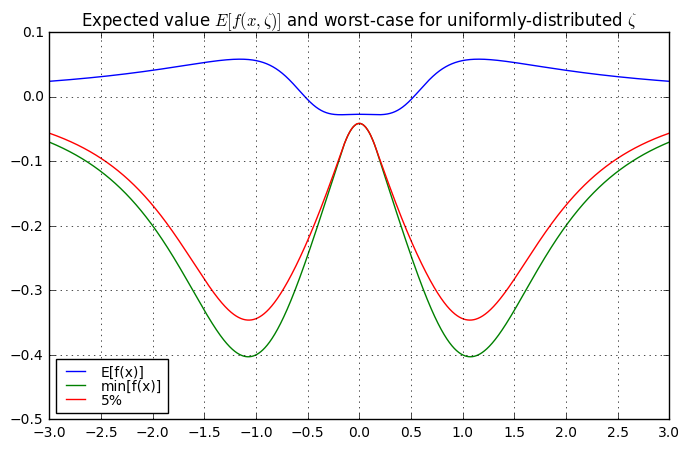
And in this case, my best choices to maximize expected value are around \( x \approx \pm1.155 \). But if we look at the previous graph showing \( f(x,\zeta) \), that’s also the value of \( x \) where there is highest sensitivity to \( \zeta \), and \( f(x,\zeta) \) can be as low as -0.4 for extreme values of \( \zeta \). If \( f(x,\zeta) \) is some net value that I want to maximize, but where there is a penalty for large negative values, then maybe I want to be risk-averse and choose \( x=0 \), where the expected value of \( f(x,\zeta) \) is negative but at least it has small variability, and the worst-case is around -0.05. Or I choose \( x = \pm 3 \) and keep a positive expected value, but try to limit the downside.
Certain countries, namely in Europe and Japan, have had central banks offering negative interest rates for holding funds on deposit. This policy seems bizarre — if I let you borrow my money, why should I pay you for the privilege? — but may be a reflection of a “safe” place to put money in 2017’s economic climate. Again, sometimes you have to optimize with risk aversion in mind.
Feeding the Golden Goose: If Sun Tzu Were a Textile Equipment Manufacturer
“Now the general who wins a battle makes many calculations in his temple ere the battle is fought. The general who loses a battle makes but few calculations beforehand. Thus do many calculations lead to victory, and few calculations to defeat: how much more no calculation at all! It is by attention to this point that I can foresee who is likely to win or lose.” — Sun Tzu, The Art of War
Our last philosophical section of this wretched essay will revisit strategic optimization.
There’s a story I heard from K., a former colleague and mentor of mine. When he was studying mechanical engineering, one of his professors, whom I will call Bright Bill, because I don’t remember his name, mentioned something that happened to him early in his career in the textile equipment industry. To clarify: Bright Bill worked several decades ago in industry as a mechanical engineer, then later became a professor of mechanical engineering, and he taught a class that K. attended, and then later on, maybe six or seven years later, I was a green young engineer working with K., who told me this story. I’ve probably got some of the details wrong, because I’m telling it third-hand. In any event, here’s the story:
Bright Bill worked for a company that made cotton-combing machinery. As far as I can tell, this kind of machine grabs a cotton fiber and somehow gets it to line up with other fibers, so it can be spun into thread. This process leaves behind short cotton fibers and other impurities, and the thread produced by the combing process is very soft and is suitable for high-thread-count fabric.
Anyway, the grabbing motion of the machine is done by a part called the nipper, and the speed of the combing machine is measured in nips per second. More nips per second is better, at least if it’s done properly, because this means the machine can produce more of that high-quality cotton thread in any given day. The textile industry has been doing this by machine at least since the mid-1800s.
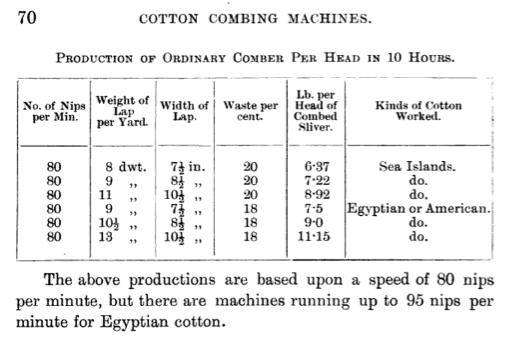
Bright Bill comes into this story as a young engineer specializing in cam design, and apparently, after a flash of insight and some hard work, he figured out how to improve the speed of the cam mechanism so that he could increase the speed of the machine by quite a bit. I don’t know the exact numbers, but let’s say it was improved from 120 nips per second to 300 nips per second. Bright Bill went in to see his boss, Austere Joe. Bright Bill showed him the design, and said, “Now we can sell a machine rated for 300 nips per second!”
Austere Joe thought a moment, and said, “This is a good improvement, and I think we should use your design, but we’re not going to sell a machine rated for 300 nips per second, we’re going to advertise 150 nips per second.”
Bright Bill was puzzled. “But why? It can run at 300 nips per second, I’m sure of it.”
“I believe you,” said Austere Joe. “But we’re going to sell our next machine rated at 150 nips per second. Then all our competitors are going to see this and work hard to make their machines get to 150 nips per second; maybe one of them will work at 160 or 170 nips per second. Then when that happens, we’re going to make the same machine but change the nameplate and allow it to run up to 200 nips per second. And they’ll see that, and eventually catch up, and when they do, then we’ll bump ours up to 250 nips per second. And they’ll catch up to that, and then we’ll sell equipment that goes up to 300 nips per second. By then maybe we’ll find another improvement to outcompete them. If we put out a machine right away at 300 nips per second, we’ve blown our lead in one shot. Got it?”
When I heard this story, I was in my early 20’s, and it was one of the first times I had heard something about the intersection of engineering and business strategy. Let’s say you’re proposing some type of software optimization. You may think you have lots of information:
- an estimate of the existing execution time of some part of the software (perhaps as a function of one or more variables, like number of simultaneous users, or requests per second, or number of data points)
- an estimate of how much faster you can make it
- profiling evidence to back these estimates up
- how often the code in question executes (every time some critical feature runs? on system startup? once in a blue moon when someone goes to an advanced UI page and does a manual query for all information?)
- an estimate of how much work it is going to be to make the change and test it
- what kind of architectural changes (if any) are needed
- what kind of risks are associated with the change
- your confidence level in all of the above information
and this is all fine and dandy; you’re doing exactly the right things, but it’s still not enough.
One of the things I learned over the years is that as an engineer, it is a real privilege if you get to make a major engineering decision. Many of these decisions will be made by managers or chief architects, or vice-presidents, although if you prove yourself competent, you’ll be asked to present different alternatives, and if you are trusted enough you may have the responsibility of making a major decision yourself. It’s not that engineers are viewed as inferior, it’s that major decisions involve major consequences that can put the future of a business at risk, so there should be checks and balances, in order to avoid decisions that lead to disaster from the whims of one person. (Just ask Nicholas Leeson.) Because these types of decisions tend to have fuzziness about them; if it were completely obvious and objective how to make the decision, they’d spend about 30 seconds making the decision and move to the next one. The big risky decisions are strategic in nature, not tactical, and are hard to measure; they involve things like trying to trade off and prioritize competing criteria like cost, reliability, time-to-market, and so forth.
In an ideal world, all that prioritization gets done beforehand, so by the time you get into engineering work on a project, the trade-offs are fairly straightforward to decide. But sometimes it’s not. One aspect I would make sure to understand, before jumping into a new project, is in which of the following categories that project falls:
- an exercise in system integration, where time-to-market is critical, and the most important thing is getting features to just work
- an exercise in system optimization, where performance (speed/cost/reliability/etc.) is critical, and the most important thing is making a new product work well enough to be viable, or improving an existing product to improve performance
- both of the above
If the last of these is true — project needs to get to market as fast as possible, and it needs to also meet some challenging performance criteria — then I would run away and find another project, unless you’ve got a high appetite for risk and don’t mind failure. I’ve been on a few of these. They’re not fun, at least for me; you can end up like a mule stuck between two piles of food, starving to death while trying to figure out which one is better. Get it done right? Or get it done fast? Good luck. Or maybe they’re just marginally feasible… your team works really hard and chooses just the right algorithm, implemented with just the right optimizations and just the right 3rd-party libraries, to run on just the right hardware, and gets done just in time to put a product out — and then something happens out of the blue (library license incompatibility, or an incorrect estimate of market demand) and all of a sudden the marginal, hard-fought success turned into failure. No thanks.
If it’s a system integration project, then, yeah, follow Knuth’s advice (and Don Not’s advice) about premature optimization; wait until there’s evidence of a problem before you try to spend time on optimizing software performance. Somehow this seems to be the alleged norm in today’s software world, especially when it comes to services offered on the Internet. I’m skeptical.
If it’s a system optimization project… well, that’s going to require some optimization work. Duh. The key here is really staying in tune with your manager and/or chief architect so you know what kind of problems you should be solving.
Good engineering managers and engineers are both problem solvers, but they handle things a bit differently. Good engineers will go and sharpen their proverbial pencils, and figure out some neat new way of doing things. Good engineering managers will look at the problems that are causing engineers to get stuck, and they’ll bring a perspective that as engineers we can’t seem to see. Maybe it’s connecting two people that they notice are facing similar situations, something like, “Why don’t you go talk to Ezekiel up on the third floor? He just ran into a logging problem that sounds similar.” Or maybe it’s keeping the team focused or prioritizing things: “Okay, we can’t have both speed and low cost… from what I understand, this customer says he wants low cost, but if push comes to shove, he needs speed. I’ll talk to him and confirm this.”
Anyway, managers love when you give them options that are all wrapped up and ready to go. Let’s say you can make some change X in the software in 3-5 days and expect it to speed up the system by 10-15%. Great! Maybe you never end up making change X, but your manager is collecting an arsenal of options, to pull the trigger when it’s necessary. If your company is competitive, it has a Golden Goose. Out come the golden eggs at one end: improvement after improvement. The thing is, it’s really painful to try to make those improvements right when they’re sorely needed. Everything stops and now you’ve got to solve Problem A. And then another more important one, Problem B, comes along, and now you have to put Problem A on hold, figure out how to deal with Problem B, then figure out how to re-engage with Problem A. Or you have a not-so-great manager that shares his bright idea with you: Hey, Fast Eddie’s not really doing so well on Problem C, which isn’t that important, so why don’t you let him have a go at Problem A, and then you can focus on Problem B? And then you end up having to deal with both of them, Problem B which is your responsibility, and Problem A, because you’re going to need to help Fast Eddie understand all the work you started, and help him muddle his way to a solution. I’ve known my share of Fast Eddies. But those are the kind of things you have to deal with, when the direction changes each week in order to deal with some new crisis, and all you’re doing is Just-In-Time engineering. If this happens too often, your Golden Goose will strain herself and have a prolapsed oviduct. Ouch.
How do we keep the Golden Goose happy and healthy?
I am a big fan of this mythical idea (and I knew of two companies that actually practiced it, at least for a year or two) of separating out research and product development:
- Allocate part of your staff — either on a permanent, or a rotating basis, whatever — to researching solutions, and avenues toward solutions, to foreseeable problems or improvements
- Keep good records of the results of that research, so it can be applied
- Allocate the rest of your staff to product development, including applying that research
The thing about strategic optimization, when it’s part of an intentional line of research, is that it can really change the whole dynamic of debate, from one of premature optimization, to expanding possible options.
Assuming you have good strategic advice from managers or chief software architects for which areas of your product need improvement, research is a good thing, and it helps cultivate a storehouse of options that can be taken. If one of those areas is improvement in execution time, then you should still be using some kind of profiler to measure that improvement quantitatively, but be creative and think of different ways to make software better. Maybe it is only 1% here or 2% there, but these sorts of improvements add up. Or there’s a small potential improvement, but it’s so widely applicable that the implications become very large. For example, the major Web browers each have Javascript engines that have been improving over the last few years. I would be curious to see how their benchmarks have improved with each small change, and I’d be willing to bet that many of those improvements have had only a small effect. But in aggregate, when there are 3 billion people using the Internet, the implications of even a 1% speed improvement are huge. Less power consumed. More people willing to access sites that are slightly faster. Companies providing more features that are more practical with a faster JS engine. There are a whole bunch of technological advances which have happened because of repeated incremental improvements: LED efficiency, WiFi speeds, IC feature size and Moore’s Law, electronic component density, the list just goes on and on. Who knows if any of it would have happened if the engineers in question had dismissed their ideas as one of premature optimization.
And maybe this idea is obvious. But the tone of what I hear in the programming community on the topic of premature optimization seems to imply that nobody has time for anything, unless it can help what they’re working on right now. Which is just sad.
At the same time, there are all these articles on how some person or group has made a successful optimization, often as an academic or pedagogic exercise. Here are just a few ones I’ve run into recently:
- Eli Bendersky, Adventures in JIT compilation: Part 1 - an interpreter (2017)
- Félix Cloutier, How do compilers optimize divisions? (2017)
- Google, Mobile Analysis in PageSpeed Insights (2015?)
- Carsten Haitzler, GOTO is awesome - 2 to 3x faster (2016)
- Daniel Lemire, Removing duplicates from lists quickly (2017)
- Lockless, Inc., Branchfree Saturating Arithmetic (2016?)
- Evan Miller, Hackers and Canvas (2013)
- Evan Miller, Premature Optimization and the Birth of Nginx Module Development (2011) — ironically, despite the title, this doesn’t really sound like an instance of premature optimization; instead he describes an initial difficult but successful optimization, that was later obsoleted by a more clever and simpler optimization.
- Chris Wellons, Small-Size Optimization in C (2016)
- Erik Witt, The Lazy Man’s Guide To HTTP/2, CDNs and Browser Caching (2017)
- Erik Witt, Building a Shop with Sub-Second Page Loads: Lessons Learned (2016)
We are in kind of a bipolar situation here (there’s Eeyore and Tigger again!): on the one hand, we don’t have any time to optimize unless there’s clear evidence that it’s necessary. On the other hand, look what so-and-so did in his blog! So which is it? And how do we know when to invest in some particular avenue of optimization? I don’t have a strong answer, but I hope that this article has given you some food for thought.
Case Studies
I’m going to end with a few brief descriptions of some optimization efforts that I’ve worked on recently, just for some examples. For comparison of execution speeds, I have a Lenovo W520 laptop with an Intel Core i7 2760QM quad-core processor (8 threads).
Details left out because (1) they’re proprietary, and (2) this article is long enough already.
Project A: Java UI with Code Generation
Project A was a program in Java that worked along with a set of Jython scripts to generate C code. I worked on the team developing the Jython scripts.
-
Time to generate C code was on the order of 2 seconds on my Lenovo W520 running on AC mains power. When running on battery, on a slower PC, it could take 7-10 seconds.
-
This was an annoying delay that would affect many people.
-
I profiled the code generation process, and somewhere between 0.7 and 1.5 seconds of it was Jython. The reason for this wide range is that I couldn’t get an exact measurement; there were Jython callbacks, both into functions my team had written, and into the interpreter itself just to get at data, and I didn’t have any way to intercept those easily to get a sense of how much time they took to run.
-
Jython was used for rapid prototyping; most our team members had Python experience but no Java experience, and staff time for development was at a premium. We found we could handle things much more rapidly when we could do it ourselves in Jython, and release an updated package of Jython scripts, than when we had to split problems between a domain expert and a Java software programmer. Occasionally we did have to turn to Java (either because of execution speed, or because of more delicate interdependencies with other aspects of Project A), and in this case, the challenges became how to review and test the implementation, because we didn’t know how to review the Java code, and the Java programmers couldn’t look at their code and decide whether they had implemented our calculations correctly. Two people are sometimes slower than one.
-
We made some proposals for potential speedups, but decided not to pursue them yet, as there were other areas of software development that were higher priority, and the delay was something we felt our users could live with.
Summary: Potential for execution time optimization was analyzed, but actual optimization effort deferred (less important than other work)
Project B: Use of the Python multiprocessing module for Monte Carlo analysis
Project B was some Monte Carlo analysis work I had to do, with the same set of Jython scripts used in Project A. Essentially I had to execute a subset of the Jython code repeatedly, over a range of 12 input parameters, to make some conclusions about the validity of our calculations.
-
Fortunately the Jython scripts were vanilla Python, so I could run them in a CPython interpreter rather than in Jython (an immediate speedup for free)
-
There was a tradeoff involving the number of samples \( N \):
- More samples took longer to compute, but gave better coverage of sample space
- Fewer samples ran more quickly, but didn’t cover the sample space as well, and yielded greater errors
If you’re familiar with Monte Carlo analysis, you know that often the resulting calculations have an error that is \( O(\frac{1}{\sqrt{N}}) \): you have to quadruple \( N \) to get twice the precision.
-
Deciding how accurate of a result I needed was a difficult problem in itself; what I wanted was for the results to be “smooth” enough that there was a reasonable signal-to-noise ratio. (for some calculations, this meant standard deviation on the order of 0.01 to 0.1 of the mean value.)
-
This was a “one-off” project: It was unlikely that many people besides me would run this analysis, and when the analysis script was complete, I only had to run this analysis once to obtain some final conclusions. This is usually a red flag for avoiding optimization effort, because it yields low ROI. But I did have to run the script frequently during development, performing edit-run-debug-test cycles. Usually what happened is that I would run it and get some useful statistics. Then I would realize I forgot to include some important variables, and I’d have to run it again. Or there were errors that I’d have to fix, so I’d need to run it in order to debug. Or I would receive some new information from my colleagues or from the analysis itself, and I’d have to modify it and run it again. So there was ROI in optimization here, because when my analysis script ran faster, it would allow me to iterate faster and complete my development work in a shorter time.
-
I finally ended up choosing a number of samples based on the time I had available, typically 2 - 60 minutes, depending on what I could do while I was waiting. If I was developing the script itself, I would keep runtimes short, so I could iterate quickly, maybe only 2-5 minutes, depending on what I needed. If I was using it to gather data, then I’d run it longer.
There were three types of optimizations I considered.
-
One was to decouple my numerical analysis from visualization of it. I dumped the results of the Monte Carlo analysis into a file, and then when I wanted to graph it, I’d always graph from the file. This was an easy optimization, and that way I could develop the graphs for a report quickly, without having to wait each time to regenerate the data.
-
Another was that I considered implementing Chandrupatla’s method in a vectorized form. Some of the preprocessing I had to do, before calling the methods contained in the Python/Jython package, involved finding the root of a nonlinear scalar equation. The Scipy library has a function called
scipy.optimize.brentqwhich is written in C to be lightning-fast, but it calls your Python function some number of times (usually in the 10-30 range), so its speed of execution depends on the execution time of that function, and I wasn’t sure whether this would be a bottleneck in the overall time of execution in my analysis. Thebrentqfunction also doesn’t work in a vectorized manner; it runs and computes a single scalar root of your equations. I was considering running it in a vectorized form, so I could give it a vector of parameter values, and have it converge to a vector of roots, each root corresponding to the parameter in the same position. In the end I did some profiling, and concluded that it wouldn’t have much benefit based on the calculations I needed. -
Finally, there’s the GIL — this needs some further elaboration.
Python has this feature called the Global interpreter lock or GIL, which makes the Python interpreter itself threadsafe. The drawback, though, is that in almost all cases it means you’re effectively using only one concurrent execution thread of your system. (You can have threads, but as long as they compete for use of the Python interpreter, only one will run at a time. Python modules like numpy and pandas that call native code can release the GIL while they are executing, so not everything causes contention for the GIL.) In my case I had a quad-core PC capable of running 8 threads, so I was only using 12.5% of my PC’s capability, and it was taking a long time to run. The idea of running 8 times as fast is attractive… especially since each sample in my Monte Carlo analysis had an independent, identical calculation on a randomly-generated set of input parameters. So I looked at the multiprocessing module, which essentially sidesteps the GIL by running separate Python processes, and communicates batches of inputs and outputs between them. The downsides here are
- you have to write your program so it can be calculated in batches (output batch = function of input batch)
- everything has to be serializable (some object types in Python are not)
- this slows down due to communication speeds, if data transmitted/received is very large
- you have to figure out a good batch size (large batches = greater memory allocation but lower communications overhead, small batches = less memory allocation but higher communications overhead)
- it makes it harder to debug
In my case, none of these were a big deal except the serializable part, and even that only took me an hour or so to figure out how to accommodate that requirement. If I had to debug anything other than the use of multiprocessing, I could run it in a sequential mode.
Once I did this, the resulting Python code could calculate at a rate of about 1.9 milliseconds per sample using 7 threads — I learned the hard way that you want to leave one thread free, otherwise the OS is very unresponsive. My sequential code using only 1 thread took approximately 6.4 milliseconds per sample. So there was a speedup of 3.4× vs. a theoretical increase of 7×. Not as satisfying as I would like, but worth the effort; I’ve run several million samples worth, so it’s saved me several hours of waiting so far (this project is still not complete), and I can get my 1000000-sample runs done in about half an hour, instead of an hour and 45 minutes. Or 100000-sample test runs in a bit over three minutes, instead of taking ten and a half minutes.
All of the random number generation still takes place in the parent process, although it can churn out batches of a million parameter sets, in the form I want, in less than 4 seconds (4 microseconds per parameter set), which is a fraction of the time it takes to run those Python scripts I’m trying to test.
I did run the cProfile module on my analysis script in sequential mode in a 10000-sample run; there weren’t really any surprises here except that it only slowed execution down by about 45%. I figured that profiling would slow my program down by a factor of 5-10, perhaps enough to impair the validity of the profiling result itself, so I was wrong about that. The top twenty functions ordered by CPU time (tottime, which excludes calls to subfunctions) took 46.9% my program’s execution time, and fell into these categories:
- Python scripts used in Project A: 14 out of the top 20, totalling 34.6% of CPU time
- The top-level script running my Monte Carlo analysis: 2/20 totalling 3.8% of CPU time
- Functions involved in root-solving: 2/20 totalling 3.1% of CPU time
- Python functions
mapandisinstancewith various callers: 2/20 totalling 2.35% of CPU time
In terms of total aggregate CPU usage, both of the following were in line with my expectations:
- The function that called each of the Python scripts in Project A, took 66.0% of total CPU time – I could try to optimize the Python scripts used in Project A, but we’re trying to keep those easy-to-maintain and understand.
- The root-solving process took another 11.9% of total CPU time
I’m not sure how I could get both cProfile and multiprocessing to work together and help me understand if there’s any obvious bottlenecks in the way I use multiprocessing.
So I’ve probably reached the point of diminishing returns for speeding up my test script.
Summary:
- Even a one-off project can benefit from optimization, because of repeated iterations during the development cycle
- Profiling with
cProfilewas helpful to confirm my expectations, but yielded no real surprises except that profiling didn’t slow things down much - Python’s
multiprocessingmodule was a straightforward solution to distributing CPU load among several processor threads, without adding significant development work or program complexity
Project C: High-speed Serial Communication
Project C was a high-speed UART-based serial communication link between a dsPIC microcontroller and software running on a PC. The microcontroller would send samples of data at a fixed rate; the PC software would log and analyze that data. A small fraction of UART traffic was bidirectional consisting of commands and responses between the two actors. This project used a proprietary communications protocol.
Optimization on the microcontroller side was fairly limited, and included these efforts:
- Use of DMA to automate transfer of a data buffer to the UART for outgoing transmission, and from UART to another data buffer for incoming reception
- Use of the dsPIC’s CRC module to speed up CRC calculation
Optimization on the PC side was more interesting. I wrote the bulk of this software in Python, for purposes of rapid prototyping, but all of the performance-critical systems leveraged Python modules that are implemented as extension modules outside the Python language (running native code typically compiled from C). This is a typical pattern in Python:
-
Data logging: I used the
pytablesmodule for data logging in a compressed HDF5 file. -
Numerical analysis: Some of the numerical analysis I implemented using the
numpy,scipy, andnumbalibraries. (Usage of thenumbalibrary deserves some more detail, but I’ll leave that for another time.) -
Communications: I wrote a Java program to relay messages between the serial link and my Python application, via ZeroMQ sockets. This needs some more explanation:
Python support for serial (UART) communications is not very good. There is pyserial, which is very easy to use, but it is not very fast, and my initial attempts to use it showed that it was a real CPU hog at high data rates. There were also some robustness issues involving nonblocking reads from the serial port, but I don’t recall exactly what they were.
Java’s support for serial communications isn’t very good either, although the solutions available are reasonably fast. The software development world has essentially neglected serial communications in favor of TCP/IP and the Internet, which is not only a shame, but a hindrance to the entire embedded systems community. (The recent “Internet of Things” craze appears to be trying to sidestep this, with a TCP/IP stack inside every toaster, weather gauge, sprinkler system, and so on; you also have low-power things like ZigBee, but we’ll see if UART communications ever completely goes away.) Java contained the javax.comm specification back in 1997 to handle serial communications ports on a PC, but Sun abandoned implementation support, and there’s no standard implementation out there. Neither Sun nor Oracle turned their base classes into interfaces that can be used as an abstraction layer for third-party implementers. I have used the RXTX library on occasion, but it’s no longer actively maintained, and does not handle USB-to-serial adapters well, crashing the JVM when the USB connection is unplugged. Fortunately the purejavacomm library, although it’s somewhat of a niche library with a very small user community, provides a very similar interface and I have found it very robust.
The adapter program I wrote in Java, read and wrote data to the PC’s serial port, and relayed it using the ZeroMQ messaging system for inter-process communication. (I used jeromq on the Java side, and pyzmq on the Python side. ZeroMQ was developed by the late Pieter Hintjens, and is a high-performance, low-complexity layer over regular TCP sockets, that lets you send messages without having to worry so much about the details of transmitting and receiving them.) This adapter program handles low-level tasks like parsing and constructing UART packets, along with some occasional number-crunching for certain computations that overtaxed the Python interpreter and were not easily translated to use numpy/scipy/numba for performance gains. As a result, I was able to offload some data processing from Python and get it to run in Java with less than 1% of total CPU usage.
Summary: Python is a good systems and “glue” language, but can be slow for processing-intensive computations. Offloading this data processing can be done through several strategic optimization techniques, such as using libraries like numpy, scipy, numba, or by implementing the required computations in another process using a faster language implementation like C/C++ or Java. (I tend to avoid programming in C and C++ on a PC for various reasons, but the major one is that it taxes my short-term memory and attention while implementing low-level tasks such as memory management, when I need those mental capacities for high-level problem-specific ones.)
For what it’s worth, I rarely try to perform any tactical optimization in Python; either my software is fast enough, or I have to look to some change in architecture (strategic optimization) to make things faster.
Wrapup
PLEASE don’t be like Don Not and misquote Donald Knuth by stating “Premature optimization is the root of all evil” while you run off to your next task. It’s turned into a very unfortunate sound bite. Knuth has some superb and well-stated points in his essay from which this quote is taken — again, that’s the December 1974 article, Structured programming with go to statements, in ACM’s journal Computing Surveys. If you’re going to quote the full sentence — “We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.” — please cite your source and link to the Structured programming with go to statements article. And whether you’re trying to advise others, or keep it in mind yourself, don’t forget about the sentences that come after:
Yet we should not pass up our opportunities in that critical 3%. A good programmer will not be lulled into complacency by such reasoning, he will be wise to look carefully at the critical code; but only after that code has been identified. It is often a mistake to make a priori judgments about what parts of a program are really critical, since the universal experience of programmers who have been using measurement tools has been that their intuitive guesses fail.
Knuth’s advice has remained relevant in the several decades since its publication, but please remember that although it applies to tactical optimization of execution time (fairly low-level details faced during the implementation phase of programming), there are many situations in strategic optimization where it can be misleading and unnecessarily discouraging:
-
Speculative optimization is a bet that sometimes pays off, and if kept to a small fraction of project time, can be an appropriate use of staff resources (especially as a diversion for bored engineers… would you rather have them exploring potential optimization goldmines, or surfing Reddit for cat memes?)
-
Measurement problems:
-
Uncertainty in measurement
-
During the initial stages of a project, where architectural optimizations are important, and the system in question is still under construction, it may not be possible to make representative measurements
-
Rare cases sometimes need optimization, but the only way to measure these is to ensure they actually occur during profiling
-
Information overload (too much raw information about execution speed, with no clear path to analyzing what might reduce it)
-
Profiling is only an indirect indicator of potential performance gains: we measure how long software takes to execute, but we can’t measure how long optimal software would take to execute — no easy way to find out potential speedups — and we can’t measure how difficult it is to make such an optimization
-
-
The 3% heuristic may be incorrect in some cases; some systems are denser with respect to critical code that impacts execution time
-
Problems in application or value assessment:
-
Strategic optimization is more directly concerned with the somewhat nebulous idea of net project value, rather than the raw quantity of execution time; execution time is only one of many metrics leading to net project value, and quantitative data on execution time doesn’t always help in complex tradeoffs with other performance criteria
-
Architectural correction/confirmation (the “AB problem”) and learning are valuable by-products of complete or partial optimization efforts; becoming proficient at software optimization requires practice
-
Translation from execution time measurements to net project value is a function of time and circumstance; a static estimate of net project value can become invalid and obsolete when applied more universally
-
Over-reliance on hard profiling data undervalues the ability of experienced engineers to perform thin-slicing (the “Blink” effect) to investigate avenues of optimization
-
Execution time, and its net project value, are distributions with uncertainty; the choice of what to optimize can be highly sensitive to project assumptions, system parameters, and degree of risk aversion of the project stakeholders
-
Successful organizations use the optimization process as a means for accumulating competitive advantages (“feeding the Golden Goose”), and can use a separation of research and product development as a buffer for more gradual application of the output of a sporadic and bursty process
-
There are multiplicative and feedback effects (synergy!) that can transform small optimization gains into larger gains in net product value
-
Optimization should be done with return on investment (ROI) in mind, and as part of a wider engineering/business strategy should not be overlooked. Don’t let the sound bite keep you from making continuous improvements toward a better world!
Related Reading
-
Joshua Barczak, Stop Misquoting Donald Knuth!, January 2015
-
Bozhidar Bozhanov, Not All Optimization Is Premature, November 2012
-
Charles Cook, Premature Optimization, 2002
-
Joe Duffy, The ‘premature optimization is evil’ myth, September 2010 — recent comments on Hacker News are worth perusing also, including this pithy summary: “Keeping performance in mind when considering design alternatives is never premature.”
-
Max Galkin, What is premature optimization, September 2014
-
James Hague, “Avoid Premature Optimization” Does Not Mean “Write Dumb Code”, August 2011
-
Randall Hyde, The Fallacy of Premature Optimization, ACM Ubiquity Magazine, February 2009 — Hyde and a few other authors mistakenly attribute the Knuth quote to Tony Hoare, but it is Knuth’s statement.
-
Oleksandr Kaleniuk, “Premature optimization is the root of all evil” is the root of evil, September 2016
-
Dustin Marx, When Premature Optimization Isn’t, November 2012
-
Steve McConnell, Introduction to Code Tuning, from Code Complete, 1993
-
Randall Munroe, XKCD #1691, June 2016
-
Joseph Newcomer, Optimization: Your Worst Enemy, 1999
-
Oliver Philippot, Premature optimization? Did you see your code?, November 2016
-
Wikipedia, Program optimization (When to optimize) — I don’t know who wrote this section, but they were very concise.
© 2017 Jason M. Sachs, all rights reserved.






- Comments
- Write a Comment Select to add a comment
This was a good read. But there are a couple things that I think get missed, and this article skips over them as well:
First is that there is an implicit assumption that programmers will be able to optimize when optimization is called for. This is contrary to my experience.
In my experience it takes a lot of practice to be decent at optimizing code, and if not optimizing is the default, then many organizations will find themselves with nobody that is up to the task when the chips are down.
As an example, I was called in to help with a performance problem on some hardware I had designed. In the the past I would also have done the programming (in assembly) but the company was transitioning to using C for embedded control and this was among the first. A low performance microcontroller (8051) had the task at boot up of spoon feeding data stored in EPROM to a TI 34010 graphics processor that stored it's code in VRAM. It was taking over an hour to load a few megabytes.
The main problem turned out to be that the programmer had used a integer modulo function to check every single 32 bit ROM address for a 15 bit page boundry. This made for compact, nicely readable C, that ran so slow that it was several days before they realized that the processor wasn't actually crashing.
My first cut at improvement was to add a counter for the page length...so the modulo function got replaced by a simple decrement and compare. This improved the boot-load time to under a minute, which was deemed acceptable. 3 different programmers marveled over the fact that my change, which added another variable, and 3-4 lines of code was ~100X faster. They were not interested in my explaination that a modulo is a division function, and that a 32 bit divide is going to be dog slow on an 8 bit processor...all they could grasp was that fewer lines of code should run faster.
The second issue is that most after-the-fact optimization will consist of various band-aids....maybe you unroll a loop, or replace a calculation with a look up table. This will yield incremental speed improvements. It is not uncommon, though, that the root problem lies in the basic structure of the program, and if a better structure had been chosen at the outset, it might yield an order of magnitude improvement, and no optimization would be required.
An example of this I encountered recently is a conveyer belt based mixing process. Components are added to the mix at various points along the conveyer. It is desired to maintain accurate records of what mixture is delivered at the end of the conveyer. A sizeable FIFO was used to track components as they were added and moved off the end of the conveyor.
But instead of using pointers to the head and tail of the FIFO like any sensibly trained programmer, the fellow was shifting the FIFO contents by copying one address at a time, so that the data literally moved through memory at the rate of the material on the belt. This is of course a very natural way to do it, but it is hideously inefficient. Instead of rewriting the program, the fix was to buy a faster processor.
So I like to spend some time up front thinking about what an optimal approach to the problem might be...and what is non-optimal about proposed approaches. This gives me a good shot at ending up with code that won't need an optimization pass later.
The second thing is that I try to squeeze in some optimization on everything I write. This keeps me in practice, and I learn ways to easily make later projects more efficient as I am writing them on the first pass. It this way, optimization becomes an iterative process over a career, not just on a project-by-project basis.

All great points, and thanks for the detailed comment!
To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:








