



The Missing Agile Conversation
Contents:
- Executive Summary
- Manager Summary
- Developer Summary
- Background
- A Better Way Forward
- Having The Conversation
- Topic Checklist
- Capturing Information
- Breaking Up Stories
- Spikes
Executive Summary
Agile practices use stories as units of development, typically tracked in a system like Jira or more simply on index cards or post-it notes.
Stories consist of a brief description, one to a few sentences. They don't contain details sufficient to allow a developer to implement them. They're not meant to be detailed specifications. The Agile practice is to defer details as long as possible, because conditions may change.
That's the definition of agility, the ability to adapt to changing conditions as needed. Agile doesn't mean doing things in less time. Rather, it means not doing things that need to be discarded because they're no longer valid under current conditions.
Specification work done up-front risks being out of date by the time it's acted upon and having to be discarded. While some things will be known up front, some will not, because every project is a mix of new development working with existing infrastructure and components. Meanwhile, business and technical conditions may change over time.
When a developer takes on a story to implement, that's the time for them to perform the work that has been deferred. They do this by having a conversation, a series of specific discussions working closely with the various SME's (Subject Matter Experts) who have information relevant to the story.
This is an expected activity that provides the information the developer needs to complete the story. Depending on the scope and complexity of the story, the conversation may be very brief, or it may be very involved. Regardless, it will consume developer and SME time.
The conversation cannot be assumed to have taken place implicitly, consuming no time. It needs to occur explicitly. This time needs to be factored into schedules for all parties.
The conversation lasts for the entire duration of work on the story, because new details and issues will emerge along the way. The output of the story will be the production code, test code, and documentation resulting from the information gathering and implementation work performed.
Test code and documentation capture information for both the immediate work and future work. Failing to capture them risks having to spend time later reacquiring the information.
Expecting developers to implement stories without investing the time necessary for the conversation risks project failure. This is an endemic problem in the industry, where the Agile conversation to implement a story has been missing. This results in poor implementations that don't meet customer expectations, schedule and cost overruns, and frustrating work environments with high staff turnover.
Manager Summary
Agile stories consist of a short description, one to a few sentences, like what can fit on an index card or post-it note. They're not meant to be detailed specifications. This isn't enough information for developers to implement them.
When one of your developers takes on a story, they should treat it as an invitation to have a conversation, a series of specific discussions with the various SME's (Subject Matter Experts) who have information relevant to the story.
This will consume developer and SME time. The conversation spans the entire duration of the story, requiring more time as additional details and issues arise. Depending on the scope and complexity of the story, the time may be brief, or it may be significant.
You need to allow for that time in planning and executing story implementation. Failing to do so risks project scheduling and progress.
You need to allow developers to have proper conversations. Failing to do so risks creating a frustrating, stressful work environment that results in staff turnover.
This is an expected but often overlooked part of the Agile practices, where work is deferred until it's actually needed. That avoids doing up front work that ends up being discarded because it's out of date. Once a developer takes on the story, that's the time to do the deferred work. The conversation is the way they do it.
Developers should run through a checklist of potential topics to discuss with SME's. Customize the checklist for your organization and projects. This applies across the entire spectrum of stories, from those that are mostly new code to those that are mostly integration.
Implementing the story will result in production code, test code, and documentation based on the information from the SME's and the developer's independent work. This captures the information so that other developers working on the project will be able to quickly understand how to use and work on the code. That helps accelerate onboarding of new team members.
Spikes are a way to make portions of the conversation explicit, split out into their own time-boxed stories to research specific questions. That provide additional visibility and trackability.
Developer Summary
Agile stories consist of a short description, one to a few sentences, like what can fit on an index card or post-it note. They're not meant to be detailed specifications. This isn't enough information to implement them.
You may find this this lack of detail frustrating. Rather than getting frustrated when you take on a story, treat it as an invitation to have a conversation, a series of specific discussions with the various SME's (Subject Matter Experts) who have information relevant to the story.
This will consume your time and SME time. The conversation spans the entire duration of the story, requiring more time as additional details and issues arise. Depending on the scope and complexity of the story, the time may be brief, or it may be significant.
This is an expected but often overlooked part of the Agile practices, where work is deferred until it's actually needed. This avoids doing up front work that ends up being discarded because it's out of date. Once you take on the story, that's the time to do the deferred work. The conversation is the way you do it.
You should run through a checklist of potential topics to discuss with SME's for each story. Customize the checklist for your organization and projects. This applies across the entire spectrum of stories, from those that are mostly new code to those that are mostly integration.
Implementing the story will result in production code, test code, and documentation based on the information from the SME's and your independent work. This captures the information so that other developers working on the project will be able to quickly understand how to use and work on the code. That helps accelerate onboarding of new team members.
Spikes are a way to make portions of the conversation explicit, split out into their own time-boxed stories to research specific questions. That provide additional visibility and trackability. You may prefer to use spikes in order to make everyone aware of the work that must be done to gather information.
Background
One of my big complaints with Agile stories for years across multiple companies and projects, that I see as a frustration expressed by others, has been that they lack details.
But a recent post on LinkedIn by Andrea Laforgia has resulted in an epiphany, changing both my perspective and my approach going forward. He posted a tweet from Allen Holub:
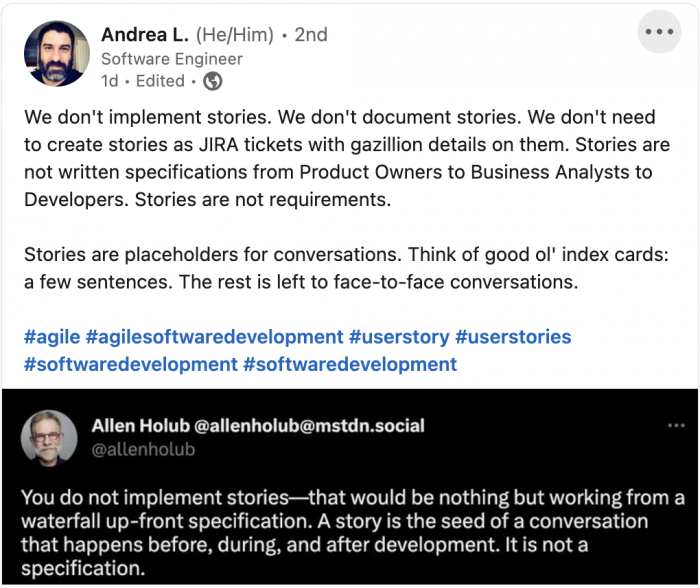
It took me a bit to fully digest this, including reading through the brief discussion in the post's comments.
These are the keys:
- "Stories are placeholders for conversations."
- "A story is the seed of a conversation that happens before, during, and after development."
This concept of having a conversation is perhaps obvious to some Agile practitioners; I've heard a couple of other people say similar things. But clearly a number of us have missed understanding this.
Why is that? Probably because we've come from some sort of waterfall-style environment where handoff of an assigned task implied that all was known about the task at that point, and the rest was merely carrying out the assignment. And then because such environments tended to produce poor, vague descriptions of what needed to be done, we just dismissed stories as yet another poor, vague way of conveying what needed to be done.
What has been missing is the conversation component. I'll pause a moment to allow those who have always understood the conversation component to recover from their horror. "Do you mean you HAVEN'T been having those conversations???"
Yes and no. Yes, in that I think many people have not had them as an expected, integral component of their work practices. No, in that people still have some form of conversation, but in an atmosphere of frustration, feeling like they're stealing time away from what they should be doing, often shortchanging it. The attitude becomes one of, "I have to waste time figuring out what this stupid story is supposed to mean when I should be getting it done."
I also think that those who have some kind of management responsibility have missed understanding that they need to take place, and that they will take non-zero time. The attitude becomes one of, "You have your assignment, quit wasting time and just get it done."
Everyone has failed to acknowledge the need to take the time to do this. The result is tension and frustration on all sides.
A Better Way Forward
Instead, let's take Andrea's and Allen's statements to heart. Instead of treating a story as a handoff, treat it as an invitation.
A story is an invitation to a conversation. Like an invitation to an event that you receive in the mail, it's brief.
The conversation will take place over the entire course of the story, with multiple people, because new details will invariably arise as you get into it. There's no point where you can declare the conversation complete and then go complete the story. The conversation is complete only once the story is complete.
Everyone needs to acknowledge this, at all levels of the organization, executive, management, and developer.
Everyone needs to understand that non-zero time will be taken by this ongoing conversation. You the developer implementing the story need to understand that, and anyone performing a management role for the project needs to understand that. Information doesn't magically transfer to you in zero time.
Critically, everyone needs to understand that other people will also be involved in the conversation, and that it will take non-zero amounts of their time as well. It will end up being a series of specific, targeted discussions with the various people who have information relevant to the story.
Who are these people? They are the "subject matter experts" (SME's, whether major or minor expertise) in the various details pertinent to the story:
- Business details
- Technical details
- Architectural details
- Functional details
- Behavioral details
- User experience details
- Security details
- Performance details
- Scaling details
- Compliance details
- What sort of details are relevant in your environment?
On any given story, the details are going to have varying degrees of significance for the purpose of implementing it. I'm coming to this in the context of developing embedded systems. "Business details" may be fairly insignificant other than the need to have a feature, but "technical details" will typically be of paramount significance, along with things like behavior, security, and performance.
Typical embedded systems projects include a mix of:
- New code.
- Integration with hardware vendor libraries, packages, and SDK's, for both the target MCU and the various sensors, actuators, and HMI (Human-Machine Interface) and MMI (Machine-Machine Interface) devices.
- Integration with third-party libraries, packages, and SDK's.
- Integration with internal company packages and IP (Intellectual Property).
- Integration with existing code already implemented.
Most projects are building on some kind of existing base. Completely new projects from scratch are relatively rare. Even those are leveraging existing libraries, packages, and SDK's. A complete embedded system that contains only new custom code is virtually non-existent.
This is true for other types of software systems as well, but is particularly true for embedded systems because at some point, they are tied to the bare metal of the hardware. Abstraction layers provide isolation between the hardware-independent and hardware-dependent components, in the same the way that a desktop or server operating system provides isolation between the application and the hardware that the OS runs on. But you still have to know how to work with those abstraction layers through their API's, just as you have to know how to work with an OS through its API's.
A given story will have varying degrees of new code and integrations. At the extremes are two types of stories:
- "All new code", that still must fit into the existing architecture and integrate with other components through their API's.
- "All integration", that still requires some new code to pull the components together in the existing architecture.
In between is the full spectrum of stories that have more or less new code and more or less integration work. To implement a story, you need to have information about all of those aspects.
That need frames the overall conversation, and drives the specific discussions you have with the SME's.
Having The Conversation
The conversation is going to be an iterative spiral. That applies to both the SME's who you need to talk to, and the topics of specific discussions with them.
It starts with identifying the initial SME's and topics, and learning about what's needed to implement the story. Then as things progress, you may identify additional SME's and topics, or additional details you need from the previous SME's. Remember that this continues over the entire course of the story as you deal with the different parts of it.
Some discussions are going to be very quick, just a few minutes face-to-face or a quick email exchange. Some are going to be more involved, maybe a whiteboard session for an hour or a prolonged email exchange. Some will require independent follow up: the SME gives you the information you need to go get more information on your own; that becomes research and investigation.
For a while, this will be an ever-expanding spiral. But eventually it will tail off as you complete the story.
How much time will all this take? It depends on the number of different SME's you need to talk to, the number of different topics you need to discuss, the depth of follow up and independent investigation required, and your level of familiarity with each topic. This is driven by the overall scope and complexity of the story.
A minimal story might just require talking to one or two SME's briefly on topics that you're already very familiar with. This might take less than half an hour of total time over the course of the story.
A more involved story might require talking to more SME's, or require more extensive discussion, or involve topics that are totally new to you (implying more learning curve), or need deeper independent investigation. This could consume multiple days over the course of the story.
Even if a topic is related to something you're familiar with, it may be in an area you haven't dealt with before, so ends up being like a new topic.
The key thing is IT WILL TAKE TIME. Everybody needs to buy in to this. Information does not magically transfer into your head instantaneously as a developer. This is not the Matrix.
Topic Checklist
This checklist of topics for SME discussions is based on projects I've worked on in the past. Yours may be different; customize it to your environment and projects, organize it in a way that makes sense for you. Grow it over time as you find other things to add.
This is the superset of all the things you might need to know to complete a story; not all will apply to every story. Some you'll know immediately, some you'll find out up front from initial SME discussions, and some you'll find out from later SME discussions as the story progresses. You may revisit things with SME's as your understanding grows.
The "what" in these refers to what exists, what is needed, what will be used, what is related, what is involved, what is expected, what is required, what is dictated, all the possible ways "what" or "how" might apply to help you as you're getting the job done. You can also discuss "what is not" in order to avoid going down the wrong path.
By the time you complete the story, you should be able to answer all the questions that apply. If you can't, that means there may be problems with your implementation.
- Hardware
- What MCU?
- What peripherals?
- What memory?
- What other hardware?
- What hardware interfaces?
- What schematics/assembly drawings?
- What data sheets/application notes?
- Development environment
- What language?
- What toolchain?
- What build system?
- What package systems?
- What deployment and debugging tools?
- What specialty tools?
- Software
- What RTOS/bare-metal?
- What drivers?
- What tasking/threading?
- What interrupts?
- What concurrency mechanisms?
- What buffers/queues?
- What files/filesystems?
- What other system resources?
- What libraries (vendor, third party, internal, etc.)?
- What packages (vendor, third party, internal, etc.)?
- What existing architecture?
- What existing examples/reference implementations?
- What API's (used or implemented)?
- What totally new things?
- What algorithms?
- What standards?
- What compliance/certifications?
- What numeric values/constants?
- What calculations/formulas?
- What data sensed, and what filtering and signal processing applied?
- What sample rate/task cycle?
- What outputs or actuations produced?
- What statistics/telemetry?
- What streaming?
- What control models?
- What remote systems?
- What data communications?
- What protocols?
- What messaging?
- What IPC/RPC?
- What UI?
- What commands?
- What management/data/control planes?
- What build changes?
- What behavior and functionality?
- What interaction with other components?
- What security?
- What performance and timing?
- What hard and soft real-time deadlines?
- What scaling?
- What authentication/encryption/cryptography (for data at rest and in flight)
- What technical constraints?
- What external requirements (for instance from requirements management systems such as DOORS or external parties)?
- General
- What specific acceptance criteria indicating successful completion (ideally to be turned into automated acceptance tests)?
- What deadlines (especially hard deadlines that may require scope reduction to meet)?
- What does X
mean (where X is terminology, acronyms, statements, etc.)? What new technology? - What decisions?
- What flexibility?
- What else?
Capturing Information
What should you do with all the information you gather? It'll be recorded implicitly in the production code, but there are other places where it will end up, specifically in tests and documentation.
If you use a system like Jira, that can also be a place for conducting parts of the conversation, in the comments for a story. That captures it in a public record visible to others. This can be a good place for initial questions and identifying SME's.
Tests
Test code provides an excellent record. This is executable documentation. When written in a BDD (Behavior Driven Development) style, it's executable specification. It's all stored in-repo along with the production code.
This has enormous value, because the documentation and specification are both updated automatically as a consequence of working on the production code and the tests that verify its behavior. This avoids the problem of separate documentation getting out of date with the code.
At a minimum, two types of tests will record information:
- Unit tests (where "unit" refers to a unit of behavior, not an implementation unit, and each test is itself a standalone unit, not reliant on previous tests), which can be developed in a TDD (Test Driven Development) fashion. These are used along the way to drive development, showing that incremental development steps behave as expected.
- Acceptance tests (again, testing behavior, not implementation). These are used to decide when the story is done (Definition of Done). They are executable acceptance criteria.
By testing behavior, any underlying implementation that passes the unit and acceptance tests by definition satisfies the story.
Once the story is complete, the tests are an additional work product, an additional output of the story. They serve as regression tests to detect breakage that may occur during future development. They also serve as documentation for future developers. When test names are written in a BDD form, the set of names by themselves form a human-readable specification.
Documentation
Documentation captures information strictly for human consumption. This is the place to convey information that isn't captured in tests, as well as to summarize architecture, design, implementation, and alternatives considered but not used.
While Agile emphasizes working code over comprehensive documentation, that doesn't mean there should be no documentation. To quote Michael Nygard, "Agile methods are not opposed to documentation, only to valueless documentation."
No matter how well done and how self-documenting, the code itself should not be considered the only documentation. The target audience is future team members (including yourself in 6 months after you've gone on to other things). Any documentation you produce will accelerate their ability to come on board, understand the system, and be effective.
This is knowledge transfer from the SME's, through you, to others. The goal is to provide a roadmap to help them navigate the code and understand what it's doing and why. Otherwise, they may need to repeat a significant portion of the conversation and spend time to reacquire the knowledge. Don't throw it away.
There are two types of documentation:
- Automatically generated.
- Manually written.
Ultimately, people have to put in the time to write the information that will drive the documentation, but where possible automated tools and simple structured templates minimize the work required.
Two types of automatic generation tools are Doxygen and PlantUML. Both require human-created input. Doxygen generates documentation about the code based on tags included in comments. PlantUML creates graphical UML diagrams from a simple text language.
Diagrams can convey an enormous amount of information succinctly, as well as illustrate specific scenarios in the code. They also illustrate structure at several levels, from system architecture block and layer structure, to data structure.
Diagrams can be incorporated into a lightweight formatted document such as Markdown or AsciiDoctor to organize the information and add brief textual description and narrative. This can be used to create architecture documents and design documents that communicate the results of the story.
ADR's (Architecture Decision Records) are a lightweight method for capturing decisions, along with their context and consequences. See adr.github.io and architecture-decision-record for more information and templates.
The set of Doxygen documents, architecture and design documents with diagrams and text, and ADR's give future developers a guide for working with and on the code. Rather than spending large amounts of time reading through the code and figuring out what it does and how to use it, the documentation will tell them in a short amount of time what it does and how to use it. Then when they need to read parts of the actual code, they will know where to go and have a huge amount of context. They will have that roadmap.
Not every story will create an independent set of new documents. Instead, the codebase will contain an overall set, with document modules spread around in-repo with the code. Each story will contribute something to that set, just as each story contributes something to the code itself and the set of tests.
Breaking Up Stories
A frequent situation is that once you start working on a story, you realize it really has multiple stories buried inside, or more scope and complexity than anyone anticipated; the story is not achievable in a single sprint.
This is the innocent-looking story that goes something like "Implement the left-handed hooverdexter." And as you get into it you realize that implies a whole area of cryptography you've never dealt with, using technology that's new to the company, on custom hardware using a new set of libraries and drivers, communicating with a remote server that uses a more secure authentication scheme, using a specialized build process.
That's really a bunch of different items that's going to take talking to a bunch of SME's and investigating how to work with multiple things, plus learning some new fundamental knowledge.
This is also part of the conversation. The thing to do is to break things up into separate stories.
This is part of being agile. As you work, you discover hidden work that must be done, or scope or complexity that consume more time than expected, and adapt to that. You create additional stories that are achievable within your sprint cadence. When you work on those, you may find some that need to be broken up further, more of that spiral iterative progress.
Dealing with new things may be a reason for breaking up stories. The stories need to allow time for learning about those things, for instance for learning the API of a new library, or learning the algorithm to implement some new code. Learning the new thing is part of the conversation for that story.
A story that requires learning three or four or five new things probably needs to be broken up into two or three or four stories, depending on the scope of learning required. It might just need an hour of reading through documentation. Or it might need a couple days of studying and experimentation.
If you're consistently finding that stories are taking multiple sprints, they're probably too complex, too broad in scope; you should strive for smaller, finer-grained stories.
Spikes
Agile spikes are a way to split out explicit stories with the goal of gathering information. A spike is a time-boxed research activity to answer a specific question.
A spike is essentially a formalized story to carry out part of the conversation necessary to complete an implementation story. It turns part of the conversation into a story in its own right that can be tracked, giving it project-level visibility.
Time-boxing helps manage the time investment. That allocates a specific amount of time to spend on the spike. If more information is still needed, an additional spike can be created.
In the case of a story that needs to be broken up into multiple stories, it may be useful to create a spike for the purpose of deciding how to break things up, as well as one for each of the resulting stories.
Since the conversation for a story is ongoing, it may be necessary to create additional spikes mid-story as new things come up.
The usage of spikes varies, with mixed opinions. Some organizations feel they're unnecessary, relying instead on having the required conversations as part of their normal process.
But others may find them helpful to make the need for the conversations more explicit. By making spikes a part of their regular process, they bake in explicit time and expectations for carrying out the conversations. Spikes signal to stakeholders that time and effort must be expended in order to figure out what needs to be done to carry out the implementation stories.
Spikes create additional overhead in the story management system. That may be considered a bad thing or a good thing.
It may be considered unnecessary additional overhead. On the other hand, it may be considered useful tracking and record keeping of information gathering efforts, highlighting them to everyone. Making them visible helps make them understandable to all parties.




- Comments
- Write a Comment Select to add a comment
To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:


