



Finite State Machines (FSM) in Embedded Systems (Part 1) - There's a State in This Machine!
Hardly you can find a concept so powerful yet so simple as the State Machine. It shouldn't come as a surprise that State Machines are so widespread, what may came as a surprise is how many bad implementations of this concept I found over the years.
Quick Links
- Part 1: Finite State Machines (FSM) in Embedded Systems (Part 1) - There's a State in This Machine!
- Part 2: Finite State Machines (FSM) in Embedded Systems (Part 2) - Simple C++ State Machine Engine
- Part 3: Finite State Machines (FSM) in Embedded Systems (Part 3) - Unuglify C++ FSM with DSL
- Part 4: Finite State Machines (FSM) in Embedded Systems (Part 4) - Let 'em talk
In this post, I'll try to go through the basics, present a simple state machine, and evolve its design until you get a basic minimal, but sound implementation. I'll comment and motivate each step so that you can reach the level you are more comfortable with or make different design choices for your code. In a future post, starting from this work, I'll present a generic state machine engine for C++.
The nice thing about State Machines is that they have a formal mathematical definition but are very intuitively and informally described. Let's consider a single push button that switches on and off a light. The button is one, but the circuitry has two different behaviors whether the light is on or off. This is the intuitive meaning of state - given the same input, a device behaves differently (but consistently) according to its internal state.
This example brings to our attention two other features of the state machine: inputs (the push button) and outputs (the light bulb).
So we can say that a state machine is composed of three parts: a state, some inputs, and some outputs. This is neat because the interface with the outside world is limited and well-defined. If you fix the internal state, the same input will always produce the same behavior, with no surprises.
State machines are also intuitively drawn with balloons and arcs:
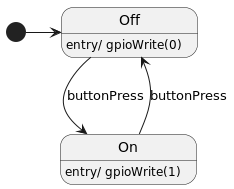
Balloons represent different states (On and Off in the picture), arcs represent transitions from one state to another, and labels on arcs define which event triggers the transition (button press).
The black disc points to the initial state using a transition with no label.
The design of a state machine usually starts with the diagram, and if you want to better grasp an existing state machine, drawing its diagram makes things much clearer.
In the diagram above you may read "entry / gpioWrite(n)". This is a way to define an action to perform (gpioWrite) each time the state is entered (entry / label). In the same way, you may define actions to be executed when the state is left via an outgoing transition. Thinking of the state as an object, the entry action can be considered the constructor and the exit action can be thought of as the destructor.
Abstracting this simple example we can say that a state machine evolves from one state to another following transitions triggered by events. In the example, the event is a button press, but abstracting the event concept, you could use any kind of input as a source for events to feed into the state machine. You can take characters from a string and translate the string into another (useful for bit stuffing/unstuffing), take messages from a communication line (and implement a protocol), and have gestures from some human-driven input device and recognize patterns.
Now that you know the basics, there are some details to enrich the model -
- You may associate action(s) with transitions.
- The same transition may be triggered by different events
- A transition may go from a state to itself
- If an event is received when the state machine is in a state where no outgoing transition is triggered by such an event, then it is ignored.
- A terminal state may be used to identify the end of state machine processing and it is drawn as an encircled disc.
What I presented here is, technically speaking, a Finite State Machine, meaning that the number of states is, well, finite. This is a limitation only if your problem requires an infinite number of states. Suppose you have a string made by open and closed parenthesis and you want to determine whether each open parenthesis has a matching close parenthesis. E.g. "(()())" -> yes; ")(" -> no.)
Since there is no limit to the nesting of parenthesis, you would need an infinite number of states to count how many open parenthesis are waiting for a matching close parenthesis.
Sometimes, like in this case, you can cheat by adding an integer variable to the state machine, but this is indeed cheating since the states of the machine are enriched by all the possible states in which an integer could be. Cheating, at least in coding, is not always bad, but you must be aware and be careful.
Let's try a first attempt at coding the state machine:
void lightSwitcher()
{
int lightOn = 0;
while( true ) {
gpioWrite( lightOn );
if( justPressed() ) {
lightOn ^= 1;
}
}
}
This is short and quick to write but somewhat obfuscates that this is a state machine. State, events, and transitions define a state machine, but we can see no explicit mention of any of them. This is an "implicit state machine", meaning that there is a state, but it is hidden in the conventional program state.
Implicit state machines, even simple ones, are hard to get right and are difficult to scale because the parts are not properly divided in the code. Usually, it is easy to miss corner cases or transitions. Debugging them is hard because the state itself is not clear.
Let's try first to disentangle the state and make it more evident -
enum class State
{
Off, On
};
void fsm()
{
State state = State::Off;
gpioWrite( 0 );
while( true ) {
if( justPressed() ) {
switch( state ) {
case State::Off:
gpioWrite( 1 );
state = State::On;
break;
case State::On:
gpioWrite( 0 );
state = State::Off;
break;
}
}
}
}
Although more verbose, this code has the advantage of clearly identifying the state and the transitions (i.e. where the state changes).
This could be fine for a simple state machine but doesn't scale when the number of states and transitions grows. There are two additional, and related problems:
- first, this code fetches directly the events from the hal interface (
justPressed()), this makes it hard to test the code, to set up the test you need to mockup the hal interface; - second, the loop keeps spinning, you can add a delay or some waiting code, but this would block the execution from monopolizing the CPU (or the thread, if you have such a luxury).
To improve the design, the state machine can be rewritten as a class that is fed with events. In this way, we leave the burden of waiting and retrieving events from the environment to someone else. This also makes it easier to test the machine:
class LightSwitcher
{
public:
enum class Event
{
ButtonPressed
};
void feed( Event event )
{
switch( mState ) {
case State::Off:
if( event == Event::ButtonPressed ) {
gpioWrite( 1 );
mState = State::On;
}
break;
case State::On:
if( event == Event::ButtonPressed ) {
gpioWrite( 0 );
mState = State::Off;
}
break;
}
}
private:
enum class State
{
Off, On
};
State mState{State::Off};
};
You may have noticed that I swapped the order of checking - in the previous example I checked the event first and then the state. Here I check the state first and the event next. In this example, we have just an event, so the advantage of this order is not evident. State checking first leads to a better organization and improves locality since all the code related to a given state is in the same place.
This is the basic level I recommend for writing state machines. OnEntry/OnExit are not present, but if the FSM is simple, like this, you can use transition action, i.e. action associated with the state transition.
This code does not rely on any external component or library and this is very convenient when you need a quick solution or you have to quickly patch an existing code base.
Considering that the state machine may grow, and thus each state can become more complex, it makes sense to extract single states. So that each state becomes a function that accepts the event and returns the next state.
class LightSwitcher
{
public:
enum class Event
{
ButtonPressed
};
void feed( Event event )
{
switch( mState ) {
case State::Off:
mState = stateOff( event );
break;
case State::On:
mState = stateOn( event );
break;
}
}
private:
enum class State
{
Off, On
};
State stateOff( Event event ) const
{
if( event == Event::ButtonPressed ) {
gpioWrite( 1 );
return State::On;
}
return State::Off;
}
State stateOn( Event event ) const
{
if( event == Event::ButtonPressed ) {
gpioWrite( 0 );
return State::Off;
}
return State::On;
}
State mState{State::Off};
};
Note that state functions do not directly alter the state, they could, but I prefer not to let them do it. The reason is because the state is critical information and I don't want it to become a shared variable. Keeping state evolution under control by restricting its change from a single point improves the readability and maintainability of the state machine. Whatever implementation you do, never let code external to the state machine, change the state machine state.
This example scales a bit better with a clear separation for each state. The design could be further improved by extracting and turning into a component, the part that handles the state transitioning from the actual functionalities implemented by the state machine. This approach is interesting because the state machine component may be reused everywhere a state machine is needed, leaving the programmer to implement only what makes that state machine different from the others.
In the next post, I'll proceed in this direction using some C++20 code.
In this article, we have defined what a state machine is and how can be implemented in code. We evolved the code implementing the state machine to address concerns or shortcomings to a solution that represents a good compromise between simplicity and good design. Improvements in the design will be the matter for my next post.




- Comments
- Write a Comment Select to add a comment

Hi Massimiliano,
Thank you for an article about state machines. I'm always very glad to see this fascinating subject being discussed.
However, from my many years of experience with state machines in embedded systems, the biggest issues are not so much with the state machine implementations (although here definitely the devil is in the details!). Instead, the biggest issues are with the code surrounding state machines.
This comes up immediately right in your introduction to state machines, where you have while(true) { if (justPressed()) {...} }. For all I know, the function justPressed() is called millions of times per second, but it's not clear how often it returns 'true', so it's not clear how often the internal "state machine" runs. In some designs, justPressed() might return 'true' as long as the switch is pressed (which means millions of times per second for a state machine) and not at all when the switch is released. In other designs, the function justPressed() returns 'true' only upon the transient when the switch is depressed. But this means that the function has a side effect of clearing some internal flag indicating the state of the switch. Now, any such 'flag' is a problem because it might be subject to race conditions, as most likely the flag is set by an ISR (but cleared in the while(true) loop).
My point is that the code surrounding a state machine is tricky, but it is critically important. (There is a big difference between running a state machine millions of times per second and only once a switch is pressed, isn't it!) Such issues make or break designs based on state machines and therefore are truly interesting and relevant for any practical use of state machines. I hope you address them head-on in your upcoming state machine articles. I'm looking forward to it!
--Miro Samek

Hi Miro, thank you for your comment.
Indeed you are right, there is a lot to write about. I wanted to focus on the reasons to prefer an articulated state machine design over a quick and dirty loop, and my next article goes on in the same direction, neglecting what happens outside the state machine but setting solid boundaries so that something like the "justPressed()" approach is discouraged. However, the use of state machines in embedded environments, with interactions and concurrency issues, makes a fascinating argument for another post.
PS. I know your work since the "Dr. Dobb's
Journal" times and always find it inspirational. So it means a lot to me
that you spent your time reading my article and commenting it.
I agree that a clean separation between the state machine logic and the surrounding code is the first, obligatory step. And yes, absolutely, this is the logical place to start and I'm looking forward to your take on the design of the generic "state machine interface". And of course, I'm also curious how you'll handle the various state machine types ("input-driven" state machines vs. event-driven state machines")
But, as your blog post promises future posts, I'd just like to encourage you not to stop with only state machine implementations (as most discussions of state machines do.), but also show how to integrate state machines into the wider system context. Giving people just the state machines (however nicely implemented) is like giving them cars without the infrastructure of roads and gas stations. Without such infrastructure, most people will (rightfully) conclude that cars are pretty... useless. And they would be right!

To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:


