



Help, My Serial Data Has Been Framed: How To Handle Packets When All You Have Are Streams
Today we're going to talk about data framing and something called COBS, which will make your life easier the next time you use serial communications on an embedded system -- but first, here's a quiz:
Quick Diversion, Part I: Which of the following is the toughest area of electrical engineering?
- analog circuit design
- digital circuit design
- power electronics
- communications
- radiofrequency (RF) circuit design
- electromagnetic compatibility (EMC)
- control systems
Is it analog circuit design? Issues like noise and component tolerance can make life really hard for a circuit designer. Perhaps it's digital or RF or EMC, all of which have weird "black-magic" aspects for handling high-frequency signals. Or control systems -- the toughest-rated classes at the university I attended were regularly cited by students as the advanced control systems courses, which sported lots of matrix algebra and weird things like H∞ and Lyapunov functions... but on the other hand, many practical control systems aren't that much more complicated than a PID loop. Or what about power electronics, where there's dangerous voltages and you have to use skills from high-frequency, analog, and control systems design?
In my opinion, the toughest area of EE is communications. (You probably guessed that because of the title. We'll get to packets after a short interlude....)
Why? Because all but the simplest communications systems have a huge amount of complexity, and yet unlike most of the rest of EE, it involves deceptively simple concepts. At least in power electronics some of the dangers are obvious.
Quick Diversion, Part II: Communications can't be that hard, can it?
Here's a simple concept: you have a train tunnel with two tracks, and you want to keep trains from crashing into each other. One track is dedicated to northbound trains and the other to southbound trains, so at least you don't have to worry about two trains having head-on collisions.

But a train can still run into the one ahead of it. Trains take a long distance to stop, so very early on there were signaling systems developed for situations like this. One at the Clayton Tunnel in England in the mid-1800's had a signaling system, where each end of the tunnel had someone stationed to set an indicator to red or green to tell trains to stop or go, with automatic telegraphs between the two stations to indicate one of three messages:
- train is present in the tunnel
- tunnel is clear
- is there a train in the tunnel?
Pretty simple system. At any given time, the tunnel either has a train traveling in it, or not. The messages allow the two signalers to communicate to notify each other when a train has entered the tunnel and when it has exited the other end. Foolproof, right?
In 1861 there was an accident at the Clayton Tunnel. It happened because there was an assumption that there would never be more than one train in the tunnel at a time. This is an abnormal system state, but it happened when two trains entered the tunnel, and once it happened, there was ambiguity about when the tunnel was clear: the man at the entrance knew there were two trains in the tunnel, but the man at the exit did not; the man at the entrance could not inform the man at the exit that two trains had entered; the man at the tunnel exit signaled the tunnel was clear when he saw the first train go through; the man at the tunnel entrance thought this signal meant both trains had gone through, and he let a third train through, which hit the second train. Oops.
It's a fascinating story, part of the introduction of the book Design and Validation of Computer Protocols, by Gerard J. Holzmann. Perhaps this story will get your guard up about how easy communications is.
A warning and a disclaimer
I'm going to repeat this a few ways:
It's very difficult to design a correctly-operating communications scheme.
Communications design is hard to get right.
It's downright tricky!
Not only that, but it's tricky for me, so my disclaimer is that I'm far from an expert on the topic.
So the rest of this article is about one specific aspect of communications design which is easy, or can be easy.
But first we have to show more specifically why it's hard.
Framed!
Framing is the ability of separating data into pieces. You can't really talk about framing, without bringing up the seven-layer OSI model. Many of the communications concepts are denoted by acronyms, like TCP and IP and HTTP (the "P" in all of these stands for Protocol), and each of these can be classified into one of seven layers, all the way from the transmission of bits at the lowest level (layer 1 = physical layer) to sending email or asking for web pages at the highest level (layer 7 = application layer). Framing is at layer 2 (data link layer).
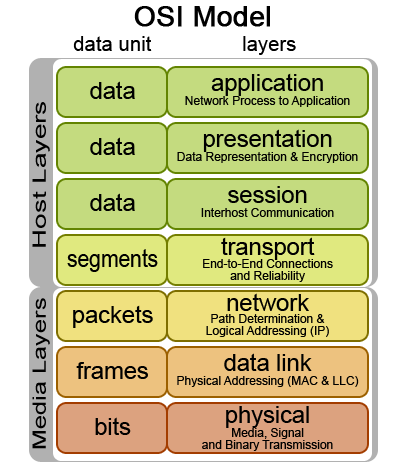
Consider RS232: the lowest level of RS232 communications is the fact that it's a two-wire single-ended signal for each direction of data sent. The bits sent are represented by voltage levels generated from the transmitter at +5 to +15V to represent a "0" bit, and -5 to -15V to represent a "1" bit. (The receiver has to interpret +3 to +25 as a "0", or -3 to -25 as a "1".)
The physical world forces us to deal with voltage, but the RS232 standard lets us think of it in 0 and 1 bits.
The next level up deals with bit timing and byte/word framing: RS232 bits are sent out at a fixed rate per data word, with a certain number of start bits (start bits are "0"), followed by a certain number of data bits, followed by a certain number of stop bits (stop bits are "1"). Words may arrive asynchronously; during the space between words the line should be at the "1" state. The most common flavor of RS232 has 1 start bit, 1 stop bit, and 8 data bits: a 115.2Kbaud connection using this will therefore transmit 11.52Kbytes/second maximum, since there are 10 signaling bits required to transmit 1 byte.

So now we can send and receive bytes, without having to think about voltage levels or bits. The OSI model lets you focus on higher-level concepts as long as the lower-level concepts are handled correctly.
If you've got an embedded system talking RS232, chances are you have a microcontroller with a UART (universal asynchronous receiver/transmitter) to translate between bytes and start/data/stop bits, and a transceiver chip (like the MAX232) chip to translate the voltage levels between the microcontroller's logic levels and RS232's positive and negative voltages. All you have to do is set up the UART registers, and then read/write bytes from/to the UART's register and handle any error conditions.
Packets and streams
The UART interface gives you access, at each end of the data link, to an input and output byte stream: an endless sequence of bytes may be sent and received at arbitrary rates up to the maximum for a given baud rate. But it's up to both transceivers how to interpret those byte streams. Most communications protocols deal in messages rather than streams: the bytes are separated into packets, that represent messages, which are just sequences of bytes delimited according to the rules of the protocol.
In the printed English language, there is data framing, too: characters are divided up into words via spaces, and words are divided up into sentences via punctuation marks, and sentences are divided up into paragraphs and then chapters by other break indicators. Morse code handled data framing with empty spaces between words, and punctuation between sentences.
So what are some ways we can frame packets of data from a UART?
Well, the simplest method is to reserve characters for signaling. The ASCII character set reserves 32 control characters (33 if you include DEL), and allows 95 printable characters for whatever purpose you see fit. (ASCII is a 7-bit encoding scheme that only defines codes 0-127.)
Great -- so we can send English messages.
But now we get to the crux of packet framing -- what if you want to send arbitrary binary data? This is the hard part. What are our options?
One option is to use a plaintext-safe method of encoding, like hexadecimal, Base64, or Ascii85, all of which use printable ASCII characters to encode binary data. They're all well-specified algorithms that aren't very complicated -- the drawback is they're not very efficient. Symbol encoding efficiency is measured as (# of bits of raw data) / (# of bits of data needed to encode raw data), and these have encoding efficiencies of 50%, 75%, and 80%, respectively. Not awful, but not very good.
Quick, escape!
Another option is to use plaintext packets and escape raw data bytes through some mechanism, usually a control character than means "stop interpreting the data for now, and just consider what's next as raw bytes."
ASCII has one character DLE (code 16) reserved for this purpose, and designates that the code(s) following it are interpreted as raw data. But the method of returning to normal control characters isn't specified, and it's up to each protocol to define how an escape sequence works. Here's some possibilities.
- The escape character allows one raw byte, after which interpretation proceeds as normal.
- The escape character is preceded by a length field denoting some positive integer N, and after the escape character, N bytes of raw data are received.
- The escape character is preceded by an unlikely random signaling sequence, and raw bytes of data are received until the signaling sequence is repeated.
- The escape character allows raw bytes, but if the escape character itself is in those raw bytes, it must be escaped, and raw bytes end when the escape character is found followed by a terminating character.
That last one was complicated, so let's see an example. Suppose our plaintext packets are of the form
DATA [ESC]{raw data}[newline]
where [ESC]{raw data} represents an escape sequence, and all packets are separated by newlines (ASCII code 0x0A).
In ASCII, this would be encoded by a sequence of hex bytes ("DATA " = 44 41 54 41 20) with 0x10 as an escape character; suppose our raw data were the 10 byte sequence 00 01 02 04 08 10 20 40 80 FF. Then the four methods mentioned above look like this (below I have annotated the raw data with underlining and escaping characters with italics)
44 41 54 41 20 10 00 10 01 10 02 10 04 10 08 10 10 10 20 10 40 10 80 10 FF 0A
44 41 54 41 20 31 30 10 00 01 02 04 08 10 20 40 80 FF 0A (with 31 30 representing the number "10")
44 41 54 41 20 41 72 67 68 21 10 00 01 02 04 08 10 20 40 80 FF 41 72 67 68 21 0A (with 41 72 67 68 21 representing the not-so-random signaling sequence "Argh!")
44 41 54 41 20 10 00 01 02 04 08 10 10 20 40 80 FF 10 00 0A (with a double 10 10 required to encode a single 10 in the raw data, and the raw data terminated by the sequence 10 00)
All of these are valid techniques as stated, with the exception of the random signaling sequence, which has problems if that sequence happens to show up in the raw data. (Some are even used in practice: HTTP uses a Content-Length header to allow arbitrary binary data to follow the message headers, and MIME uses a signaling sequence to delimit multipart messages.) This can be fixed by either amending the protocol to allow escaping of that raw sequence somehow, or by using a sufficiently long random signaling sequence that the probability of ambiguity is sufficiently small to be on the order of other types of communications errors.
Communication errors. Hmm.
Did I mention we have to deal with communication errors?
Let's hold off on that for a moment, and sum up this section on plaintext encoding of raw data: the plus side is that there are many possible methods. The minus side, potentially, is that plaintext always represents giving up efficiency for the redundancy of human-readability. I tend not to use plaintext encoding of packets in my protocols, especially for small embedded systems that use a UART: serial bandwidth is too precious, and the logic to transmit and receive plaintext packets can become very complicated.
42 69 6E 61 72 79 20 50 72 6F 74 6F 63 6F 6C 73 (Binary Protocols)
The alternative to a plaintext or mostly-plaintext protocol is a binary protocol, in which data is sent and received, with no attempt at trying to be human-readable.
Many serial binary protocols use a header-data-trailer packet format. The header consists of one or more bytes, which tells the receiver that a new packet has started and tells it what kind of packet it is, along with other metadata like a timestamp or packet length (if the protocol allows variable-length packets). The data is some set of data bytes associated with the packet. The trailer usually has a checksum of some sort (often a 16-bit or 32-bit CRC), and maybe a packet separator.
We could encode our 00 01 02 04 08 10 20 40 80 FF raw data sequence like this:
01 [length] [data] [CRC-CCITT-Xmodem] 00
01 0A 00 01 02 04 08 10 20 40 80 FF 81 ED 00
where 01 is a header tag for data messages, 0A is a length field denoting that there are 10 bytes of raw data, 81 ED is the CRC16-CCITT (aka XModem CRC) for the data bytes in the packet prior to the CRC, and 00 is a termination mark.
That's only 5 bytes of overhead, compared with between 10 and 17 bytes of overhead in the plaintext methods we discussed above. And it's also easier to encode and decode: the encoder is trivial, and the decoder just waits for a 00 byte to denote the end of one packet, then looks at the next byte to see that the 01 denotes a data packet, reads the length, then reads the data, reads the CRC, checks the CRC, and reads the 00 terminator.
The above packet definition supports raw data packets with 0-255 bytes of data payload. If we want to allow 65535 bytes of data, we could use a 2-byte length field. Or we could use LEB128 encoding for the length field: numbers between 0 and 127 require 1 byte, and larger numbers require more bytes when needed.
Great. We're happy.
Except for communications errors.
Framing errors

(No, not that kind of framing error)
There are ErROR_S in communications -- you cannot avoid them altogether, and you have to deal with them on various levels of the OSI model. If you're using RS232, and you get a momentary short circuit, you could get a voltage of 0, which is an invalid level, causing you to miss whatever data was there during the short. Or perhaps there's a glitch that messes up the start or stop bits so they aren't quite what's expected. That happens on the physical layer, and in both cases, the error is detectable. If there's a lot of noise, you may get a bit error which becomes an undetected byte error: a 08 byte becomes 09 or 0C or something, and you receive the wrong data.
This is the reason why error-detecting codes and error-correcting codes are used. (We won't cover error-correcting codes like Hamming codes or Reed-Solomon encoding -- they allow you to correct errors through complex algorithms that can use up quite a bit of CPU time in small embedded systems.) Probably the most common error-detecting code is a CRC. If you have packets that contain a CRC field, you can usually detect errors and mark a packet as "bad": the math behind the CRC ensures that all single-bit errors can be detected, and many multiple bit errors can be detected. Random byte errors are detected depending on the CRC length: 16-bit CRCs will fail to detect random byte errors 1/65536 of the time, and 32-bit CRCs will fail to detect random byte errors 1/4,294,967,296 of the time.
But in-place byte errors aren't the only error that can occur. One or more bytes might be missing (either detectably or undetectably). Or a receiver might have just started (or restarted) listening to a transmitter, and caught its data stream in mid-sentence, so to speak.
Let's look at that binary packet again, in context of receiving many packets. Our protocol says packets end in 00, and data packets start with 01:
.... 00 | 01 0A 00 01 02 04 08 10 20 40 80 FF 81 ED 00 | ....
Supposing we had a byte error and the CRC didn't match what was expected. What should we do -- should we throw the whole packet out and start at the end of the invalid packet? Or only throw the first byte (01) out, and try to find the next packet? In either case we have to resynchronize with the next possible packet.
Let's pretend we're the receiver. We come in at some random time and look for an 00 byte. Oh, there's one:
0A | 00 01 02 04 08 10 20 40 80 FF 81 ED 00
Look, it has a length of 01, and a binary data paylod of 02, and a CRC of 04 08, and a terminating byte of 10... uh oh, that's not a packet. Hmm. let's start again and look for the next 00, oh there it is, after the ED.
We just lost a packet, but we recovered and re-synced to our data stream, narrowly avoiding a framing error.
CRCs and terminator bytes are extra information, or redundancies, that can help us keep from having framing errors.
The problem is, they don't work 100% of the time.
Let's suppose our raw data was the 6-byte sequence 00 01 02 13 73 00. We encode this with our protocol, and get
01 06 00 01 02 13 73 00 E6 F6 00
There's a potential problem here, because this packet is a valid packet, but our raw data contains a valid packet as well -- 01 02 13 73 00 -- which has a valid CRC and a valid 00 terminator. So if we tried to resync to the serial stream because of errors, we could get a framing error and interpret 01 02 13 73 00 as a data packet containing the payload 02. This causes an undetected error at the data framing level, which can only be caught at higher levels of the protocol.
An analogy in English is if you heard this when talking to your friend Steve (What? You don't have a friend Steve? Then find one; they're useful):
...and I don't think he was going to do it, but he said he wanted to chop down the tree in your front yard.
There's those ellipses at the front of this quote. Maybe you had been daydreaming, and you just started paying attention. Now suppose you had been daydreaming a little longer, and heard this.
Chop down the tree in your front yard.
Your reaction would probably be something like "Excuse me?", at which point Steve would have said, "He said he wanted to chop down the tree in your front yard," and the situation would have been clarified, although you probably would have then asked who Steve was talking about.
As human beings, we're capable of very complex protocols, including requests for retransmission ("Excuse me?") when we detect improbable messages ("Chop down the tree in your front yard.")
But that requires complexity. A simple robot that dozed off and woke up to hear "Chop down the tree in your front yard" might go and do it, at which point you'd run after it to stop the thing, and later sue the robot company for not detecting framing errors.
Preventing framing errors
OK, so now, maybe, you believe that framing errors can cause serious problems, that can't be mitigated by using CRCs. I had an argument about 2 years ago with a coworker about this issue -- he said framing errors were BAD, I thought they weren't a big deal if you had CRCs. Then I started dealing with a noisy RS232 system, and every once in a while I got a data packet that passed the CRC check but contained garbage, because my protocol had no way to prevent false resynchronization on raw binary data in the middle of a packet.
So I started looking around for ways to prevent framing errors.
The most obvious source was to find out what the Internet uses. You're reading this article from a web server that talks via HTTP (OSI layer 7) on top of TCP/IP (layers 4 and 3) most likely on top of Ethernet frames, which have an 8-byte preamble (31 pairs of "01" bits followed by a "11") with address and length fields, a 4-byte CRC, and a 12-byte minimum interframe gap at the end, in order to deliver a 46-1500 byte payload. Works great -- hundreds of exabytes of data are being transmitted per year, many using Ethernet frames.
But that's 20 bytes of overhead just for the framing. Ugh. Too much in my situation, which had data payloads in the 1-24 byte range.
One general approach, that seemed promising to me, was to make certain that the byte sequence used to delimit data packets was only used as a delimiter and never appeared anywhere else. Never.
If 00 is the packet delimiter, and you want to send raw data containing 00 somewhere in the data packet, you have to encode it differently somehow, because you have to remember, 00 never gets used in the communications protocol except at the end of each and every packet.
OK, I figured -- maybe I'll use 01 as an escape character: for example, 00 in raw data could get encoded as 01 02 and 01 in raw data could get encoded as 01 01, and everything else can pass through verbatim.
But my data had lots of low-numbered data bytes in it, and I didn't want to double the encoded data size by having to use 2 bytes instead of 1 for encoding 00 and 01. Even if I picked an obscure byte value like 173, there was still a chance my packet size could double. Yuck.
Or I could use out-of-band signaling: RS232 has some auxiliary signals (CTS, RTS, DTR, DCD, DSR) which I figured I might be able to use somehow as framing delimiters. And I started to look for 9-bit UART communication methods (allowing the regular 8-bit data bytes + an additional 256 out-of-band control bytes). But I'd have to get them to work both on the microcontroller I was using, and on my PC, which seemed either impossible or overly restrictive.
Then I came up with an elaborate scheme for encoding a sequence of 7 bytes of raw data as a 9-byte payload, by treating them as 8 7-bit numbers instead of 7 8-bit numbers, and adding some 1 bits here and there to make sure the pattern 00 never appeared.
And I was starting to implement an encoder/decoder in software for this crazy scheme, when I ran across COBS, which stands for Consistent Overhead Byte Stuffing, which blew my approach away. COBS was described in a 1997 paper by Stuart Cheshire and Mary Baker, two researchers at Stanford. Not only do I think you should use COBS, but you should read their research paper yourself. Unlike many papers that appear in academic journals, the paper is very readable, the algorithm is very simple, and Cheshire and Baker have done their homework.
COBS, at last!
In a nutshell, here's how it works.
The byte pattern 00 is reserved as a packet delimiter. Always.
If you have a 00 byte in your raw data, you have to encode it. But instead of encoding it directly, you encode it as the length of the block of data that includes both the 00 itself and any nonzero raw bytes that precede it.
Consider the following sequence of raw data bytes:
07 09 00 01 00 00 02 03 04 05 06 00 18 22
I'm going to annotate this sequence of raw bytes with underlines to delimit blocks of nonzero data that end in 00, and add a phantom 00 at the end:
07 09 00 01 00 00 02 03 04 05 06 00 18 22 00
It gets encoded in COBS like this:
03 07 09 02 01 01 06 02 03 04 05 06 03 18 22 00
Each block that ends in 00 gets replaced by a block that starts with the length of the block, followed by the remaining bytes. The whole packet then ends with the packet delimiter byte 00.
Overhead: 2 bytes. (1 for the COBS encoding to avoid 00, and one for the 00 delimiter itself)
If you have blocks of up to 253 nonzero data bytes, followed by 00, then this is enough to encode those. If you happen to have a block of 254 or more bytes in a row, you encode that block by FF followed by the first 254 nonzero bytes, then encode the rest of that block with COBS. (So FF + [254 bytes of nonzero data] stands for the 254 bytes of data without any trailing zeros.)
That's it.
Overhead for a packet of length N, including the 0 delimiter, is always between 2 (most often) and its worst-case value of 1+max(ceil(N/254)) = 2 for packets from length=0 to 254, 3 for packets from length 255-508, 4 for packets from length 509-762, etc.
If you have packets that are always less than 254 bytes in length, the encoding/decoding algorithm can be simplified by treating the data blocks as starting with 00, and the raw data packet starting with a phantom 00:
phantom 00 + raw packet:
00 07 09 00 01 00 00 02 03 04 05 06 00 18 22
encoded packet:
03 07 09 02 01 01 06 02 03 04 05 06 03 18 22 00
Same encoding, but note that now the nonzero bytes line up -- so the encoding algorithm goes like this:
- Output a 00, record a pointer to that byte, and initialize a length counter to 1.
- If the raw input packet has no bytes remaining, end.
- If the next byte in the raw input packet is zero, goto step 7.
- The next byte in the raw input packet is nonzero: output that byte without changing it.
- Increment the length counter.
- Goto step 2.
- The raw input packet contained a 00: overwrite the last output 00 with length counter value.
- Goto step 1.
The decoding algorithm is just as simple, and I leave it as an exercise for the reader. (Remember, this only works for packets that are of length 253 or less, or which have no sequences of 254 nonzero bytes.)
If you want to include a CRC (and I strongly recommend this), you can, just use it as part of the raw data before you encode it with COBS.
What's the big deal?
You can still have errors using COBS: if there are enough byte errors, even if you use a CRC, you can get a packet that looks valid. This is true for any communications protocol: change the data from valid packet to another valid packet, and you change the meaning.
The difference is that because COBS is a robust scheme for avoiding framing errors, whether you detect a packet with byte errors (very likely, if you use a CRC) or not (very unlikely), there is guaranteed resynchronization to the next error-free packet received after a packet delimiter. The alternative is to live without a robust scheme for avoiding framing errors: once you receive an erroneous packet, additional packet errors can continue to occur until you resynchronize with the packet boundaries. And a CRC and header/terminator byte alone is not sufficient to avoid getting tripped up when the byte used for termination is also allowed to be part of the data packet's payload.
Use COBS, and may it serve you well.
Happy framing!
images of tunnel, OSI model, start/stop bits are all from Wikipedia -- please consider making a donation to the Wikimedia Foundation to support its continued existence




- Comments
- Write a Comment Select to add a comment
Yet your article is impossible to find, even though this topic is narrow. I had to scour my history list to get it back.
Think about your SEO


http://eli.thegreenplace.net/2009/08/12/framing-in-serial-communications/
COBS Python Module
https://pypi.python.org/pypi/cobs/
The current project I am working on uses COBS and specifies zero bytes as the start and end of frame markers (section 3.5 Lower Level Framing). Everything between these zero bytes is COBS encoded. The end of frame zero isn't necessarily needed, but on a shared bus it has some use. The share bus use case is for device UARTs that flag transmit complete when the transmit shift register is loaded (instead of when it has completed transmission). On a shared bus, there needs to be a mechanism to shut off the transmitter. If the transmitting device has a receiver loopback and affixes at least 2 zeros to the end of a packet then a processor can shutoff the transmitter when a first end of frame zero is received. As a failsafe, the transmitting devices can shutoff the transmitter if it is about to send the second end of frame zero, because this means it didn't see the first end of frame zero.
The COBS paper shows a variation on the COBS encoding scheme, which eliminate pairs of zeros. When I initially read this, it brought to my mind that I could use variations on the COBS encoding scheme with addition benefits if I understood the sparseness and structure of a data set.
But what "max" is calculated here? 1+max(ceil(N/254))
Regards?
To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:

