



C Programming Techniques: Function Call Inlining
Introduction
Abstraction is a key to manage software systems as they increase in size and complexity. As shown in a previous post, abstraction requires a developper to clearly define a software interface for both data and functions, and eventually hide the underlying implementation.
When using the C language, the interface is often exposed in a header '.h' file, while the implementation is put in one or more corresponding '.c' files.
First, separating an interface from its implementation is a good way to 'self document' the code.
More importantly, while the compiler does not have to know a function definition when processing a function call, it should know the function prototype to generate correct code. This is especially true for the return value and the parameter types. The calling convention is important too, when differing from the default one. Note that the source can still compile (eventually with warnings) when function prototypes are missing, but the generated code may not be correct.
The purpose of this post is to show that hiding implementation, while a good software engineering practice, requires the compiler to generate extra instructions, not part of the useful computation. By using function call inlining, part of the induced overhead can be avoided without damaging the software interface. This practice is especially useful for computations that are a few cycles long.
Overhead associated with function calls
When a function is called from a different compilation units (the usual case), the compiler generates a call instruction. Be it relative, indirect or absolute, the instruction operand (the branch destination address) is resolved by the static linker when merging the compilation units ('.o' files) together. For simplicity, we omit the case of dynamic libraries, and assume that the address is fully resolved by the static linker. The called function finally returns the calling site using a branching or a specialized return instruction.
Depending on its internally maintained state (registers currently in used, calling convention ...) and configuration (optimization level ...), the compiler generates extra instructions to save and restore context, and to pass arguments. This is applicable to both the caller and the called function. In the called function, context saving and restoring are known as prolog and epilog, respectively.
All these added instructions are not part of the useful computation and are considered as overhead. This is pictured by the following diagram:
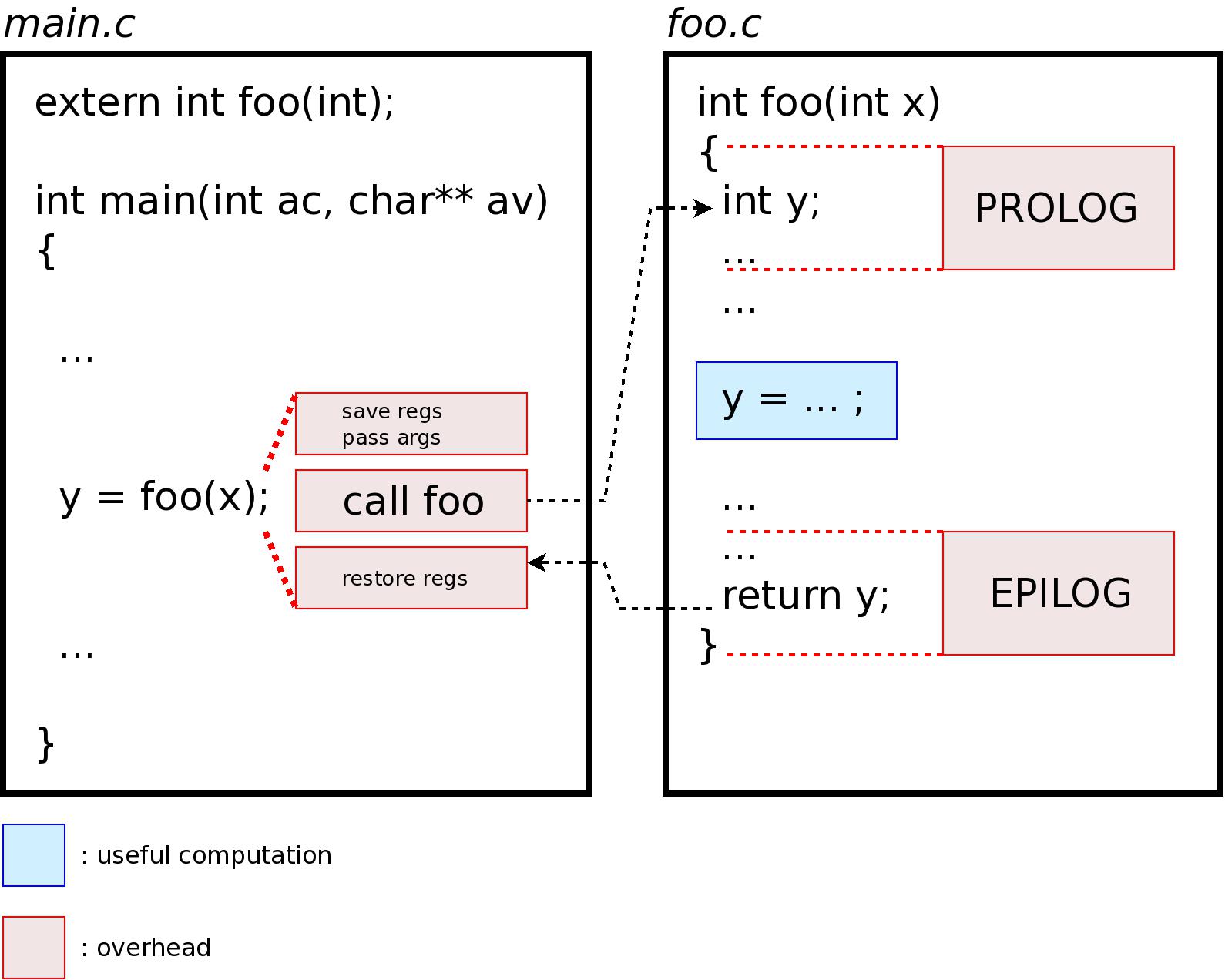
For a developper looking for performance, this overhead may not be acceptable, especially for functions that are only a few cycles long. One way to avoid it while keeping the software interface clean is to use function call inlining.
Generally, a compiler is said to inline a function when it substitutes the definition in place, removing the need for branching instructions and the associated context management. This is illustrated by the following diagram:
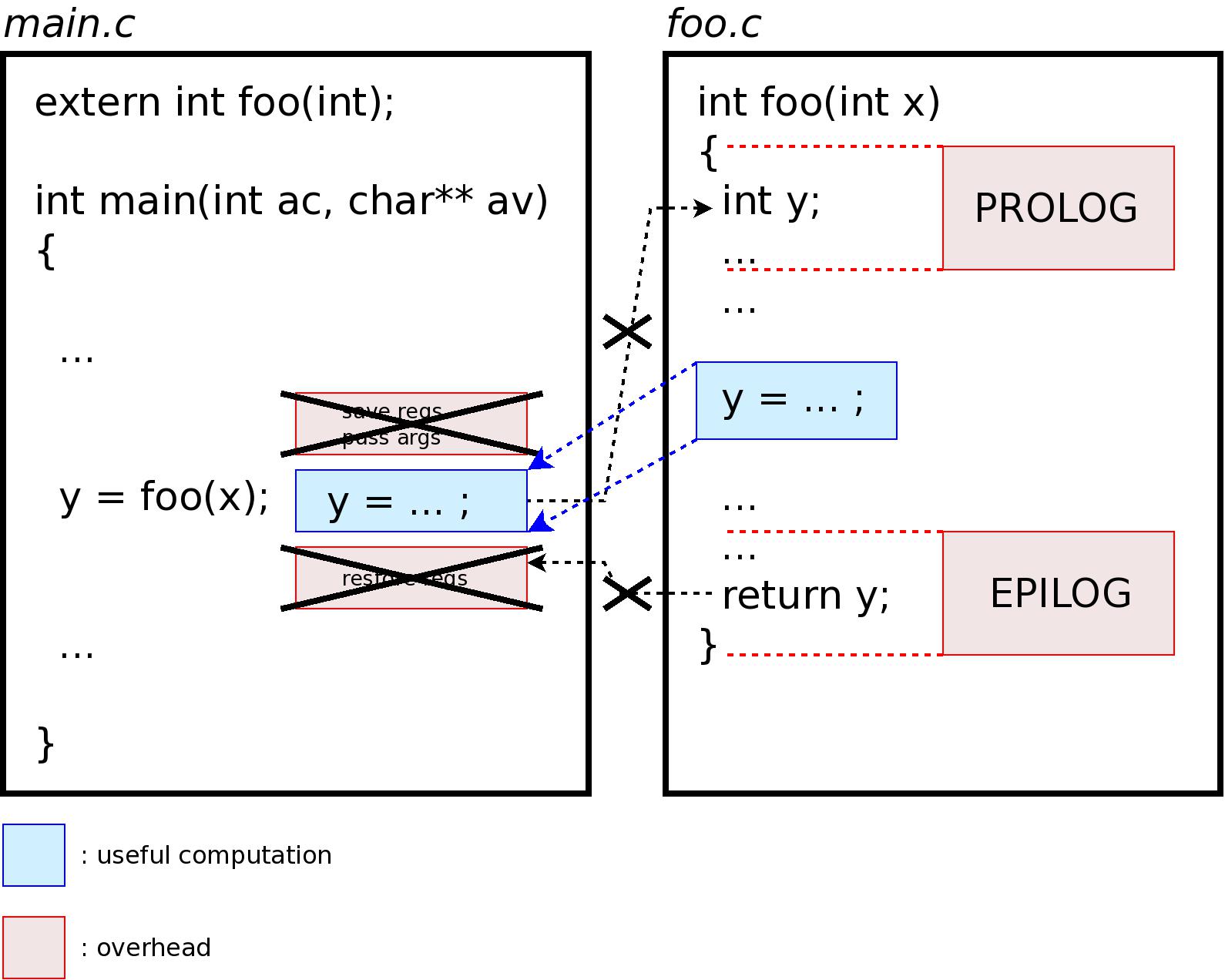
Knowing the function definition, the compiler can even perform optimizations such as constant substitution, smarter register usage ...
Inlining mechanisms
For inlining to occur, the compiler has to know the function definition at the time of use. It means that the definition must be in the same compilation unit as the caller. For obvious reasons, copy pasting a function body across the source files is not a good practice. Thus, file inclusion is used to make the definition known to the compiler.
One way to inline a function is to define it using a preprocessor macro. You are sure the code is substituted in place by the preprocessor, with no intervention from the compiler. One problem is that macro parameters are not typed. Also, macros tend to require tricks that make them difficult to read and maintain.
A preferred way is to define functions inside the included header file. This way, the compiler knows its definition at call time, and can substitute it in place. However, putting function defintions in the header file kind of 'break' the interface versus implementation separation practice. A possible convention is to put the inlined code in a separate '.c' file and include it in the header file. The header file must be properly guarded, or multiple definitions will occur at link time. Also, note that the Makefile (or equivalent) must properly handle these files as object generation rules prerequisites.
Whatever the chosen approach, there are several ways to tell your compiler a function call should be inlined. It takes place when declaring the function, using the inline keyword. Details differ among compilers. The documentation for GCC is available here:
I routinely use the static inline approach, with optimizations enabled at command line (-O2 flags). If enabling optimization is a problem, the always_inline attribute can be used, as described in the documentation.
Example
A very simple example shows how to implement what we have seen so far. Both the default and the inlined versions of a bit testing function are compiled. The generated assembly code is dumped and analyzed. Note that an ARM toolchain is used.
---- file: bit.c--#include < stdint.h >---- file: bit.h--
#include "bit.h"
#if (CONFIG_INLINED == 1)
static inline
#endif
bit_word_t bit_is_set(bit_word_t x, bit_off_t off)
{
return x & (1 << off);
}
#ifndef BIT_H_INCLUDED---- file: main.c--
#define BIT_H_INCLUDED
#include < stdint.h >
typedef uint32_t bit_word_t;
typedef uint32_t bit_off_t;
#if (CONFIG_INLINED == 1)
#include "bit.c"
#else
bit_word_t bit_is_set(bit_word_t x, bit_off_t off);
#endif
#endif /* BIT_H_INCLUDED */
#include "bit.h"
int main(int ac, char** av)
{
volatile bit_word_t* x = (bit_word_t*)0xdeadbeef;
const bit_word_t s = 2;
__asm__ __volatile__ ("nop":::"memory");
while (bit_is_set(*x, s)) ;
__asm__ __volatile__ ("nop":::"memory");
return 0;
}
---- file: do_build.sh--
#!/usr/bin/env sh
# to change with your own prefix
CROSS_COMPILE=armv6-linux-gnueabi-
$CROSS_COMPILE\gcc -DCONFIG_INLINED=0 -Wall -O2 main.c bit.c
$CROSS_COMPILE\objdump -d a.out > not_inlined.s
$CROSS_COMPILE\gcc -DCONFIG_INLINED=1 -Wall -O2 main.c
$CROSS_COMPILE\objdump -d a.out > inlined.s
The default, non inlined version, generates the following code:
00008444 :
8444: e3a03001 mov r3, #1
8448: e0000113 and r0, r0, r3, lsl r1
844c: e12fff1e bx lr
main:
82ec: e59f4018 ldr r4, [pc, #24] ; 830c
82f0: e5140110 ldr r0, [r4, #-272] ; 0x110
82f4: e3a01002 mov r1, #2
82f8: eb000051 bl 8444
82fc: e3500000 cmp r0, #0
8300: 1afffffa bne 82f0
The inlined version results in the following code:
main:
82e8: e59f3010 ldr r3, [pc, #16] ; 8300
82ec: e5130110 ldr r0, [r3, #-272] ; 0x110
82f0: e2100004 ands r0, r0, #4
82f4: 1afffffc bne 82ec
First, note that the branching instructions are no longer present (default version, offsets 0x82f8 and 0x844c).
Also, since it knows the function body, GCC can make smarter decisions. It uses the ands instruction (inlined version, offset 0x82f0), removing the need for the cmp instruction (default version, offset 0x82fc).
Finally, note that the mask is automatically computed (inlined version, offset 0x82f0). In the particular case of the ARM instruction set, it does not result in a smaller code size (see default version, 0x8448).
While very simple, this example illustrates the advantages of inlining function calls. If you are interested in larger code base, I suggest you to have a look at the LINUX kernel source tree. For instance, the linked list library makes heavy use of it:
http://lxr.free-electrons.com/source/include/linux/list.h
Note that it actually uses preprocessor macros along with inlined functions. This is done to implement type based code generation (similar to C++ templates), not to reduce overhead.
If you are interested in a real world embedded application where inlining played an important role, I propose you to look at an open source project I recently worked on:
https://github.com/texane/nrf/blob/master/src/atmega328p/common/nrf24l01p.c
https://github.com/texane/nrf/blob/master/src/atmega328p/common/softspi.c
Conclusion
In software engineering, portability and well designed interfaces are especially important. Still, some parts of the source code require fine tuning to reduce overhead. The C language offers mechanisms to meet these goals, function call inlining being one of them.
However, one must keep in mind that inlining code often results in executables that are larger in size. It can be an issue on microcontrollers with limited memory resources. Whether or not to use function inlining is, as often, a trade-off.




- Comments
- Write a Comment Select to add a comment
If the inlined function it's very short or is called only in one place in the whole code, the result executable should be the same size or less, not ?


Some compilers are able to inline across modules if multi-file compilation is available. When selected, all files in a group are compiled as if they were one file. Inlining can then be done across all the files in the group.
I never use the inline keyword since it's an extra level of complication to worry about. Instead, I let the compiler choose the best method for the function.
Thanks for your comment. This article shows how a developper can direct the compiler to do function call inlining, independently of what the compiler already inlines under the hood. In this process, a developper (using plain C + GCC at least) must 1) make the function definition known to the compiler and 2) force the inlining using the mechanisms described 3) verify that the inlining actually took place. It is not only about putting or not the inline keyword

I agree wholeheartedly with the general approach and you hit the nail on the head with why inlining is important (short functions where the body of the function is around the same size or smaller than the function call overhead).
I would add one more thing to explain why you need to use "static inline" rather than just "inline". If I understand correctly it's because "inline" is just a hint to the compiler, and if you don't use the "static" keyword and the compiler decides not to inline, then you can get conflicting function definitions if you #include the inlined function in more than one compilation unit.
A job well done!
p.s. just curious -- what software did you use to create those diagrams?
for these too).
Actually, there is an error regarding the file naming: bit_inlined.c should be called
bit.c in this example, as the do_build.sh script uses a command line argument to
differentiate between the inlined and non inlined versions. Of course, it does not
go against the proposed convention, and you could have called it bit_inlined.c too.
I fixed it.
You got the point concerning the static keyword, but just to be clear I will add that
the symbol visibility is independent of the compiler function call inlining decision.
If you want to check it, compile the code at the end of this comment:
gcc -O2 -c a.c; gcc -O2 -c b.c
Using:
objdump -d {a,b}.o
you see that GCC decided to inline in both case, BUT the foo symbol is kept and
stay globally visible. Trying to link a.o and b.o together will fail because of multiple
foo definitions.
Thus, the static qualifier is independent of the inlining decision. It tells the symbol
(function or variable) name is exported to all the compilation units. The general rule
is that every symbol not part of a public interface (ie. not exported to the world outside
the compilation unit) should be hidden and qualified as static. Thus, the global namespace
is not polluted.
For the diagrams, I use DIA: http://projects.gnome.org/dia
--
-- code
--
-- file a.c
inline void foo(void)
{
__asm__ __volatile__("nop");
}
int main(int ac, char** av)
{
foo();
return 0;
}
-- file b.c
inline void foo(void)
{
__asm__ __volatile__("nop");
}
void bar(void)
{
foo();
}
To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:


