



Bad Hash Functions and Other Stories: Trapped in a Cage of Irresponsibility and Garden Rakes
I was recently using the publish() function in MATLAB to develop some documentation, and I ran into a problem caused by a bad hash function.
In a resource-limited embedded system, you aren't likely to run into hash functions. They have three major applications: cryptography, data integrity, and data structures. In all these cases, hash functions are used to take some type of data, and deterministically boil it down to a fixed-size "fingerprint" or "hash" of the original data, such that patterns in the distribution of the data do not show up as patterns in the distribution of the fingerprints. If you've got an embedded control system, most likely it doesn't need to use hash functions. Maybe you're using a CRC for data integrity. If so, you probably know enough about them already. If not, bear with me — knowing about them is good for you, like eating fiber... or maybe like touching poison ivy once and learning not to do it again. It builds character. So here we go:
Let's try to be a little bit formal here, and state these as requirements of a hash function \( H(X) \).
-
Hash functions are deterministic. For any two identical data items X, H(X) will always yield the same result.
-
The outputs of hash functions form a fixed set: If \( d = H(X) \), then d is an element in a fixed set of outputs. Usually d is an n-bit integer in the range from 0 to \( 2^n-1 \); sometimes (in modular arithmetic) d ranges from 0 to p-1, for some prime p.
-
(Statistically useful hash functions only) Statistical property: Distribution patterns in the hash function inputs do not show up as distribution patterns in the hash function outputs. Suppose we take a large number of items from a random process that has a particular probability distribution. For example, rip any page you like from a phone book, affix it to a cork board on the wall, and pick names from this page by throwing darts at it. There's going to be patterns here. You won't get last names that start with every letter. Remove the duplicates, so that you have N unique data items. Now run them through the hash function. If it is a good hash function, the results should be statistically indistinguishable from uniform random values taken from the set of hash function outputs. If the inputs are close together, like James, Jameson, and Janigan, the outputs should be unrelated.
-
(Cryptographically useful hash functions only) Cryptographic property: Information about the hash function outputs does not give any information about the hash function inputs. This is even stronger than the statistical property, where all we care about is avoiding patterns in the output. For hash functions that satisfy the cryptographic property, if there is an unknown data item X where you are told \( d=H(X) \), you are no better off predicting item X than if you did not know the hash value d. Furthermore, even if you are told X later on, it is impractical for you to find some data item Y such that \( H(Y) = H(X) = d \).
Any cryptographically useful hash function is a statistically useful hash function. Choosing the right cryptographic hash function for a given application can be tricky, so we won't talk about cryptographic applications.
Hash functions for data integrity like a CRC are usually easy, since they're well-known and well-specified. Say you're transmitting some data from a microprocessor over a serial line to another system. In addition to sending the raw data X, run the data through a hash function and send the result d = H(X) as well. On the receiver side, the received data X' is also run through a hash function. If the received value d' matches the calculated hash of received data H(X'), there is a very high probability that X = X'. In the event there is data corruption in either the received raw data or the received hash value, it is extremely unlikely that the hashes would match. 32-bit hash values make this probability one in 4 billion; if you go to 64-bit or higher, undetected data corruption is essentially negligible.
Hash functions for data structures are used to make a fast preliminary test of equality. The hash table is ubiquitous, and any computer programming language or library worth its salt, that uses associative arrays, has some kind of hash table under the hood. Hash functions are used both to spread out data evenly in the table, and also to provide quick lookup: rather than testing for exact equality (which can take a while if the data items are large, and if data access times are slow, like from a remote database), you first test for equality of the hash values. If the hash values don't match, then neither do the raw data items. If they do match, and you do need to check for exact equivalence, then you can go back and check the data itself.
In fact, probably the only time you'll ever be writing your own hash function is when you have to store some kind of custom data object as a key (not a value) in a hash table. The hash table library needs to know how to convert your data object to an n-bit key, so you should use some kind of hash function that is statistically useful. Hash functions that aren't statistically useful (like \( H(X) = X \mod 123 \)) shouldn't really be used at all. The usual technique for a hash function of a composite object, is you take the parts of the object, compute hash functions for them, and take a linear combination of the results with weighting factors that are prime numbers. Most languages/libraries with hash function support already have hash functions defined for built-in objects like integers or strings, so you just need to write a composite hash function. For example, if data item X has three fields (A, B, C), then define X.hashCode() = 43*A.hashCode() + 37*B.hashCode() + 31*C.hashCode().
If you really want to learn how to write your own general hash function, rather than using one from a pre-existing library, you should read the section of Donald Knuth's The Art of Computer Programming on hash functions, in Volume 3, under "Searching". If you get all excited, by all means, go ahead and make your own. If you read Knuth vol. 3 and your eyes glaze over, I'd recommend finding a hash function someone else has written and tested.
Bad Hash Functions
Hash functions can be bad in a couple of ways. (Again, never mind the cryptographic kind. These are just hard to get right. Don't write your own cryptographic hash function unless you're willing to defend your creation to experts in the cryptographic community.)
First, they can violate the statistical property of hash functions. This can lead to clustering: If there are N possible hash outputs, a statistically useful hash function will lead to each of these showing up with equal probability 1/N. Hash functions that aren't good enough in a statistical sense may have higher probabilities for some values. This can lead to poor utilization of resources (more memory required for an associative array, or longer search times) or more common incidences of failure than would be possible with a statistically useful hash function.
More insidious than this is a hash function that has the statistical property, but the number of output values are too small. And here's where my first story comes in.
The publish() function in MATLAB lets you convert a MATLAB file with annotated markup, to an HTML file that can be used for help documentation within MATLAB. This particular dialect of markup is quirky (I like Markdown syntax better; in fact I write these articles in Markdown using IPython notebooks) but it has some really nice features, especially the ability to embed MATLAB graphs automatically.
Anyway, publish() supports entering equations using the TeX format, and it converts them to image files for inclusion in the final HTML file. This is one of the performance bottlenecks (if you have a lot of equations, it might take 30 seconds or more), so someone decided it would be a good idea to cache the converted equation images. The thought was, I guess, if the equation doesn't change, then you should be able to just keep the final image. The problem is the way in which MATLAB chooses a filename to store these hash functions. Here's the relevant lines of code from the R2013b release of MATLAB, in the private hashEquation() function:
% Get the MD5 hash of the string as two UINT64s.
messageDigest = java.security.MessageDigest.getInstance('MD5');
h = messageDigest.digest(double(a));
q = typecast(h,'uint64');
q = typecast(h);
% Extract middle of the base10 representation of the first UINT64.
t = sprintf('%020.0f',q(1));
s = ['eq' t(6:2:15)];
This creates a string of the form eq99999 where 99999 is a 5-digit number derived from the 128-bit MD5 hash of the equation text.
What's the problem? There's 100,000 values, right? That's plenty of possibilities for equations!
Well, here's an example. Stick this into a MATLAB .m file and run publish() on it:
%% Hash collision! Boo! Hiss!
% Let's try $x = 499$, $x = 183$, $x = 506$, $x = 457$,
% $x = 807$, $x = 531$, $x = 821$, and $x = 260$.
%
% This should read x = 499, x = 183, x = 506, x = 457,
% x = 807, x = 531, x = 821, and x = 260.
And here's what results:
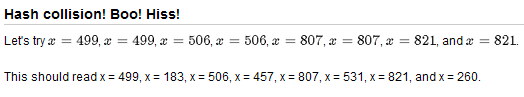
So the question here is, why does this happen?
If you have MATLAB, you can try this yourself. It should work for any release of MATLAB from somewhere back in 2007 until... well, until they fix it.
If you don't have MATLAB, let's look at a Python implementation of hashEquation():
import numpy as np
import hashlib
# Translation of the MATLAB code.
# Remember: MATLAB arrays start with index 1,
# but Python arrays start with index 0.
def crappyHash(s):
m = hashlib.md5()
m.update(s)
d = m.digest()
dtype = np.uint64
q = np.frombuffer(d,dtype)
t = '%020d' % q[0]
return 'eq' + t[5:14:2]
for n in [499, 183, 506, 457, 807, 531, 821, 260]:
eqn = '$x = %d$' % n
print 'crappyHash("%s") = %s' % (eqn, crappyHash(eqn))
crappyHash("$x = 499$") = eq17231
crappyHash("$x = 183$") = eq17231
crappyHash("$x = 506$") = eq67657
crappyHash("$x = 457$") = eq67657
crappyHash("$x = 807$") = eq49462
crappyHash("$x = 531$") = eq49462
crappyHash("$x = 821$") = eq96736
crappyHash("$x = 260$") = eq96736
What are the chances of this happening? Well, we can figure it out. Let's start with two equations chosen at random, assuming that crappyHash() is statistically useful, i.e. it maps strings to outputs which are statistically random from the set of strings consisting of eq followed by a 5-digit integer.
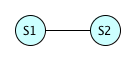
Here are two equations, represented by S1 and S2. We can pick any equation we like for S1. We'll get some number between 0 and 99999 as a result, since there are 100000 possibilities. For S2, 99999 of the possible hash values are different than the hash of S1, but the remaining possibility yields the same value; if \( H(S1) = H(S2) \), then we have a hash collision. So the chances of a collision in this case are \( \frac{1}{100000} \).
The next case is with three equations.
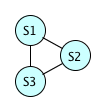
Again, S1 gives us one hash value. There's a \( \frac{99999}{100000} \) chance that S2 has a different hash value from S1. Now we have to consider S3; if \( H(S1) \neq H(S2) \), then two of the hash values are used up, and there's a \( \frac{99998}{100000} \) chance that \( H(S3) \neq H(S1) \) and \( H(S3) \neq H(S2) \). The probability that there is no hash collision is therefore \( \frac{99999}{100000} \times \frac{99998}{100000} \approx 0.99997 \); the probability that there is at least 1 hash collision is approximately 0.00003.
Four equations?

Probability of no hash collision = \( \frac{99999}{100000} \times \frac{99998}{100000} \times \frac{99997}{100000} \approx 0.99994 \), so the probability that there is at least 1 hash collision is approximately 0.00006.
Five equations?
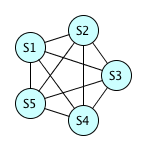
Probability of no hash collision = \( \frac{99999}{100000} \times \frac{99998}{100000} \times \frac{99997}{100000} \times \frac{99996}{100000} \approx 0.99990 \), so the probability that there is at least 1 hash collision is approximately 0.00010.
All right, this is getting a little repetitive; let's just take a look at how the hash collision probability depends on the number of equations:
def calcCollisionProbability(nmax,hash_space_size):
def helper():
P_no_collision = 1.0
d = 1.0 * hash_space_size;
for n in range(nmax):
P_no_collision *= (1 - n/d)
yield 1-P_no_collision
return np.array([x for x in helper()])
nmax = 1000
n = np.arange(nmax)+1
p = calcCollisionProbability(nmax,100000)
plt.plot(n,p)
plt.grid('on')
plt.yticks(np.linspace(0,1,11))
plt.xlabel('number of equations')
plt.ylabel('probability of at least one hash collision');
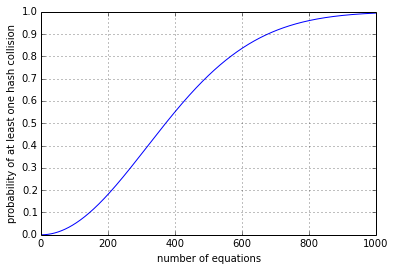
For n=50 items, the probability of a hash collision is 1.22%; for n=100 items, the probability of a hash collision is 4.83%; for n=200 items the probability of a hash collision is 18.1%. If the number of items n is much smaller than the size of the hash value set N, the hash collision probability is approximately \( \frac{n(n-1)}{2N} \), since the number of pairs of items is \( \frac{n(n-1)}{2} \), and each pair of items represents an opportunity for a hash collision. The general probability of at least one hash collision is \( p = 1 - \frac{N!}{N^n(N-n)!} \), where the exclamation point means the factorial function (n! = the product of all positive integers from 1 to n).
These are items chosen at random, and it's known as the birthday problem; a famous math brainteaser is how many people do you need to have at least 50% chance that two of them have the same birthday? (the answer is 23)
(If the items aren't random, but chosen by trying out the hash function to find collisions, the problem of collisions becomes much worse; I ran a short script to check all the equations of the form \( x = N \) with N from 1 to 1000, and quickly found four pairs of numbers with hash collisions.)
So is a five-digit hash value large enough? I would argue the answer is a definite NO. The article you're reading has 19 equations in it, up to this point; it's technical but not overly so. The odds of a collision with 19 inputs vying for 100000 hash values are around 1 in 585. It's somewhat unlikely that I would run into the problem with this article, but with thousands of people using MATLAB writing multiple files that they want to publish(), I'm sure someone has already run into this problem before I noticed it. Hopefully they noticed it and had a way to work around it by changing the equation. (Fortunately you can add space characters to the TeX source, which doesn't affect the equation outputs.) The unlucky users are the ones that had this occur, and did not notice it, introducing an error in their publish()ed documentation. MathWorks has had seven years to notice and fix it. I've filed a bug report; hopefully this issue will be resolved in R2014b or R2015a.
What about a six-digit hash value? (N = 106) Well, this lowers the chances somewhat; the 1 in 585 chance for 19 equations with N = 105 items decreases to a 1 in 5848 chance. For small numbers of items, increasing the hash value set size by a factor of k decreases the probability of collision by approximately the same factor k.
What puzzles me, is why MathWorks decided to use MD5, a 128-bit hash function (it has some weaknesses as a cryptographic hash function, depending on the application, but as a statistical hash function it's fine), and then use only about 17 bits worth of the result, throwing away the rest. Taking the entire MD5 hash function and converting it to a base 36 number (digits 0-9 and A-Z) would yield a 25-digit number (since \( 36^{25} \approx 2^{129} \)), not an unreasonably large filename for an autogenerated file. This reduces the probability of a hash collision to a really really small value (about \( 5 \times 10^{-37} \) for 19 equations) that is acceptable in practice.
Alternatively, MathWorks could have used a collision-tolerant technique. Associative arrays typically use hash tables for storing data, and it isn't acceptable for collisions to cause errors in data storage, so hash tables have to have a method of collision resolution, either storing data values with the same hash code as a list, or by using nearby empty cells in the hash table. In the publish() case, it would be fairly easy to use a filename like eq00001-001.png where the first 5 digits are a hash value, and the remaining 3 digits are a counter, and then store the exact equation source as metadata in the PNG file by using the tEXt ancillary chunk. This would give publish() a chance to make sure the resulting equation image actually came from the same equation source, rather than just blindly using a cached equation file that has the same hash value.
In other words, hash functions are good for speeding up duplicate detection, but because they can yield false positives in the case of collisions, equality testing should be used where possible, along with collision resolution. If not possible, then it's wise to use cryptographic hash functions — they're widely available and have gone through the right testing to avoid collisions except with a vanishingly low probability. And be sure you are aware that this probability is not zero.
Further Reading
Irresponsibility and Garden Rakes
Here we come to the "other stories" part of this article. I have a reputation as being a very cautious and meticulous person — sometimes too cautious and meticulous for some of my colleagues, who think I'm making mountains out of molehills, and I ought to be keeping a more practical perspective rather than worrying about improbable risks.
It is not a flaw to notice when things can go wrong. It is a flaw to become paralyzed by noticing when things can go wrong. It is also a flaw to ignore when things can go wrong. With that in mind, I'm going to let you in on something:
I'm a Microsoft basher.
Yes, I admit it. But rather than just spouting vitriol about the company, I want to share a story with you.
My experience with Microsoft and PCs started in the fall of 1988. We were using a PC at our high school newspaper to assist in desktop publishing. At the time, MS-DOS was the dominant PC operating system; a typical PC had an Intel 80286 or 80386 processor, running somewhere in the 8-16MHz clock rate, with 640Kbyte of RAM, two floppy drives and a 20-30 megabyte hard drive. Graphical user interfaces were occasional but each program had to make its own.
I bought my first PC in the fall of 1990. It was a 16MHz Zeos 80386, with 1Mbyte of RAM, a 40 megabyte hard drive, and an amber monochrome monitor, and it came with Windows 3.0 installed. At the time, Windows was, to me, a Good Thing. Most of the programs I used would run on MS-DOS, and were kind of clunky, like WordStar. I bought the computer to use Borland Turbo Pascal and continue a summer project I was working on. At the time, Borland was still alive and well*, and they offered deep discounts to existing customers. I upgraded to Turbo Pascal for Windows, which let me make GUI programs in Windows. At the time, there was no reliable IDE from Borland in Windows — you had to use the DOS IDE to compile your program, then start up Windows, run your program, and if you ran into trouble, either the computer crashed or you had to exit Windows anyway to recompile. It took a long time.
But I persevered, and eventually bought Borland Turbo C++ for Windows. I wrote a puzzle game where pressing various buttons caused other buttons to appear and disappear (the goal was to get all the buttons to disappear). I wrote two simple physics simulations for a class project; one that was a pendulum, the other a pair of rotating conveyor cylinders and a board. I learned Windows programming from Charles Petzold's classic "Programming Windows".
I went to college. I got Microsoft Word and Microsoft Excel. For what I needed, they worked, they were much easier to use than WordStar, and I don't remember crashes very much. Life Was Good.
Then I got a summer job programming, and a lot of the work was porting some software that used the campus network, from UNIX to Windows. This was back when networking stacks on Windows were haphazard, and there were a whole bunch of different vendors offering different things. (Anyone remember token ring networks, or Novell NetWare, or Artisoft LANtastic?) The Winsock API was brand new and not widely available. On top of that, it didn't interact with the Windows 3.0 or 3.1 cooperative multitasking model very well. We really stretched things trying to get our software to work. I used the Microsoft Visual C++ IDE, a big improvement over the Borland IDE, but a lot of what we needed to do was poorly documented by Microsoft, and you had to run around in circles to get something done when it wasn't easily facilitated by Microsoft's programming paradigms. It was really frustrating that we could do some things so easily and portably in UNIX, but when it came time to do the equivalent under Windows, it was like pulling teeth.
But that was on the programming side. As a computer user, I still liked Windows, and Microsoft Word, and Microsoft Excel, and Microsoft Visual C++. Oh, and of course Minesweeper.
And here's where we get to the garden rakes.
*Perhaps surprisingly, Borland is still alive in 2014, but it sold its development tools division to Embarcadero Technologies in 2008.)
Sideshow Bob
There was a 1993 episode of The Simpsons, called Cape Feare, which parodied the 1991 Martin Scorsese film, Cape Fear. The Simpsons episode had a sequence where Sideshow Bob follows the Simpsons family by hanging onto the underside of their car, whereupon they drive through a cactus patch; then, when Sideshow Bob finally crawls out from under the car, he accidentally steps on a garden rake, whacking him in the face with its handle, not just once or twice but nine times.
A few years after that, I was a junior engineer working on a report of some motor testing results, and I wanted to create some timeseries plots showing torque and speed graphs. At the time, my company had Microsoft Office 95 on each of our computers, so I went to graph the data in Excel. Creating one graph was easy. Having two graphs, however, on the same page, lined up... there didn't seem to be a way to do that. No problem: I had started hacking around using Visual Basic macros a couple of months earlier, and getting better-looking graphs seemed to be a worthy challenge.
But here's the thing: I just could not get it to work. The problem was that by default, Excel chose the placement of a subgraph's axis based on the outer dimensions of a graph (including axis labels and tick labels) rather than the dimensions of the primary graph axes. So you ended up with a graph, but it didn't quite look all neat and tidy like this Python graph I can create with matplotlib:
import matplotlib.pyplot as plt
import numpy as np
def drawxlgraph(dx):
t = np.linspace(0,1,1000)
y1 = np.vstack([np.cos(30*t+a) for a in np.arange(3)*np.pi*2/3])
y2 = t*y1
y3 = t*(1-t)*y1
ytitles = ['graph of y1',
'graph of y2\nSee?',
"graph of y3\nSome really\nlong labels\ndon't fit well"]
f=plt.figure(figsize=(8,6),dpi=80)
for (i,y) in enumerate((y1,y2,y3)):
ax=f.add_subplot(3,1,3-i)
ax.plot(t,y.transpose())
ax.set_ylabel(ytitles[i])
if i > 0:
ax.set_xticklabels([])
p = ax.get_position()
p2 = [p.xmin,p.ymin,p.width,p.height]
p2[0] += dx[i]
p2[2] -= dx[i]
ax.set_position(p2)
ax.grid('on')
drawxlgraph([0,0,0])

Instead, it looked like this:
drawxlgraph([0,.02,0.06])

So you got a nice, neatly aligned set of graph labels. But the data itself was misaligned.
And there wasn't any realistic way to specify the aligned behavior I wanted and expected. Instead, I spent a day or so hacking around in Visual Basic macros, until I finally got them to line up by drawing the graphs twice: first with Excel's default behavior, then measuring the pixel positions of the axes, and compensating to adjust the full axis bounding boxes.
Success! Or at least, I thought I had success, until I went to print out the graphs, and discovered that aligning the graphs on a computer screen did not guarantee aligned graphs when they were printed out. And there was no way to adapt my workaround to printed graphs.
WHACK!
So garden rakes it is — the sensation of running into an unexpected stumbling block, then trying a different direction and running into another one, and another; running around in circles, always unable to do exactly what you really want. You're on a computer. It's supposed to raise productivity. Where do you want to go today? You've got a task to do (like writing a report on motor testing, with some graphs), and instead of thinking about it, you're stuck thinking about stupid little stumbling blocks. Just like you'd like to go running through your backyard as a shortcut, so you can get to your best friend's house and play video games... but there you are, getting whacked in the face because your dad was irresponsible and left a bunch of garden rakes lying around. Whack! Ouch!
Garden rakes!
And thus ended my Visual Basic career. I never touched it again; shortly afterwards I had MATLAB installed on my computer, and used it instead.
But my adventures with Microsoft products continued.
Garden Rakes, part II: The Component Object Model
There are many varieties of software programming. I learned early on in my career that I wasn't cut out to work on large software applications. But I have found programming indispensable for the various "odd jobs" along the way that came up while working on other tasks. For example, over the years I've written utilities to help with debugging embedded systems through serial port communication. A year or two after the Excel Graphing Incident, I started to use Microsoft Visual C++, and learned how to use the Win32 API to access the serial port. A little later, maybe in 2001 or 2002, I decided I was going to learn how to use the Windows drag-and-drop features in my C++ programs. So I started reading the documentation in MSVC. And pretty soon I got into this thing called COM, the Component Object Model, which was Microsoft's successor to OLE (Object Linking and Embedding).
In fact, the MSDN documentation today on COM looks pretty much the same as it did then:
All COM interfaces inherit from the IUnknown interface. The IUnknown interface contains the fundamental COM operations for polymorphism and instance lifetime management. The IUnknown interface has three member functions, named QueryInterface, AddRef, and Release. All COM objects are required to implement the IUnknown interface.
The QueryInterface, AddRef member function provides polymorphism for COM. Call QueryInterface to determine at run time whether a COM object supports a particular interface. The COM object returns an interface pointer in the
ppvObjectoutparameter if it implements the requested interface, otherwise it returnsNULL. The QueryInterface member function enables navigation among all of the interfaces that a COM object supports.The lifetime of a COM object instance is controlled by its reference count. The IUnknown member functions AddRef and Release control the count. AddRef increments the count and Release decrements the count. When the reference count reaches zero, the Release member function may free the instance, because no callers are using it.
You're stuck in a little Kafkaesque universe here, with IUnknown, QueryInterface, AddRef, and Release all referring to each other, but none of these pages actually really explaining what's going on, or linking to another page that explains it. No tutorial, no example program snippets, and all the information is scattered among a bunch of web pages, each of which takes maybe 20 or 30 seconds to download. I figured somewhere in one of these web pages, there is at least one link to a page that will fill in the missing link and clear it up. I went around in circles, but could never find anything. Here it is in MSDN a dozen years later, and it looks as though nothing has changed.
I gave up. No drag-and-drop for me. Garden rakes strike again.
It wasn't until four or five years later, in 2006, that I finally ran across a sample chapter from Don Box's "Essential COM" and bought a copy of the book, and worked my way up the COM learning curve. Slowly. Why bother? Because of the promise of reusable software with multiple language bindings: I could write a software component in COM, and then use it from C++, or JSDB Javascript, or if my colleagues wanted to use it in Visual Basic, more power to them. Two years later I had a good working understanding of how to use drag and drop — along with COM and ATL and IDL and IIDs and CLSIDs and proxies and stubs and marshaling and apartments and all that what-not... and then I threw it all out the window when I discovered Java and Swing, and how much easier it was to be free of all the baggage and just write Java programs in Eclipse without having to worry about all that crud.
You can't get there from here!
So there's a question just waiting to be asked here: Why do we get stuck among garden rakes anyway?
What leads to this kind of a situation? Why does a professional software product or service become so useful and popular, and yet there are desired solutions that lie just out of reach, despite reasonable expectations of success?
There's a saying in New England when visitors from more cosmopolitan areas need directions (meaning New Yorkers in New England, or people from Massachusetts in northern New England, or any non-Mainer in Maine) , the joke is that "you can't get there from here": it's just too complicated, you'd have to know where Dexter Shoes and the Shop 'n' Save used to be, and you wouldn't be able to find it anyway. (We can get there from here, but you can't get there from here.)
If we were to draw a map of most large software products, it might look like this:
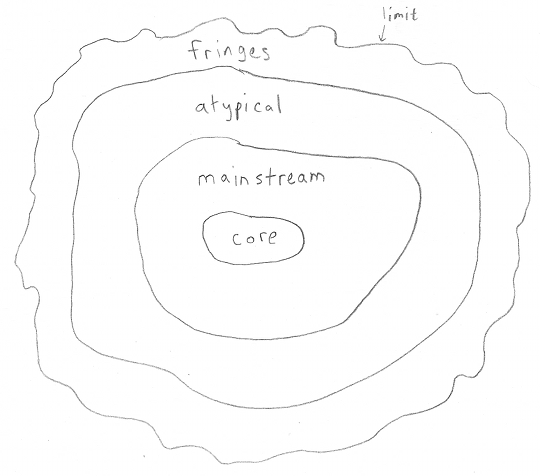
At the core are the primary functions. These are the ones that are thoroughly tested, and in the spotlight all the time.
Outside the core is the mainstream; these areas lie within some generally-accepted region of responsibility. User experience difficulties or bugs are not completely absent, but are rare, and not acceptable.
Outside the mainstream is the atypical. These areas are envisioned by the product's designers, but are less of a priority to maintain.
On the fringes are use cases the designers had not envisioned. Unfortuately, users of the product are in a bit of a bind here; it may take a bit of persuasion to convince a software company to fix bugs or add features in this part of an application.
The fringes have their limits, and here's where we can run into those damned garden rakes.
There are not abrupt boundaries between these zones; in reality it is a gradual spectrum between the core and the limits. And not all software looks like same; some of it may have a map like this, where the boundary between what is possible, and what is not, traces a circuitous path and forms irregular shaped peninsulas and inlets:
What differentiates some software from others? Some products (like Excel or COM) have tons of nasty fringe areas, and others do not.
I can think of four factors that determine how software behaves in the fringes.
The first is philosophical. Software companies have to determine how rigorous they wish their quality control to be. There's a saying, "The perfect is the enemy of the good.", and project managers always need to determine when it's time to ship, despite remaining bugs or missed features. The threshold of acceptance may be different, depending on the intended customer (consumer vs. commercial/industrial) and the market (entertainment vs. financial/medical/aerospace), and whether the company wants to maximize its financial return or its reputation.
The second has to do with complexity, which I've mentioned before. Smaller, simpler projects have fewer fringes than large, complex ones. It's that straightforward.
The third — which I've also mentioned in the context of complexity, and is very similar — is Fred Brooks's idea of conceptual integrity in the Mythical Man-Month:
I will contend that Conceptual Integrity is the most important consideration in system design. It is better to have a system omit certain anomalous features and improvements, but to reflect one set of design ideas, than to have one that contains many good but independent and uncoordinated ideas.
The commitment to conceptual integrity is a critical determining factor to uniform quality in a software product. Without conceptual integrity, the fringes can become a region of bandaids and last-minute patches. At its best, it is the result of too many well-intentioned cooks at work. At its worst, it can border on symptomatic irresponsibility creeping into the borders of software design.
The fourth factor is the degree to which software must be backwards-compatible and support legacy uses. Problems which are easy to resolve in a new product, can be devilishly difficult in a product that is constrained by its ancestors. It's part of the reason why roads are awful to navigate in New England: one road may change directions and names within a matter of a few miles, because the road was laid out in 1735 between Leicester and Ainsbury for the farmers to move their livestock the long way around the swamps and to the market; in Ainsbury it's called the Leicester Road, and in Leicester it's called the Ainsbury Road, of course. In the American Midwest or West, the surveyors — not the farmers and cows — laid out the roads, generally on a grid, and as a result finding your way around tends to be a lot easier. Whereas New England is stuck with the settlement patterns from the 1700's. Legacy software has similar problems; because software tends to be very brittle with respect to changing interfaces, poor choices and unlucky choices early in a software product can restrict its behavior for years.
Let's have another look at Microsoft again: I don't know what goes on inside the big software factory in Redmond, so I'm not sure I can make claims about their commitment (or lack thereof) about conceptual integrity, but Microsoft products tend to be very large and complex, and backwards-compatible.
And I believe Microsoft's record shows that they are focused more on profit and supporting the mainstream with the promises of new features, than on quality, security, and fixing bugs.
Does this mean we have less expensive software as a result? Quite probably. But over the long run it can be harmful. When a small company with a commitment to quality and conceptual integrity goes head-to-head with a large company that wants to meet mainstream demand and no more, it usually means the small company goes out of business, perhaps to everyone's loss. The world needs a variety of solutions. It's not limited to software, unfortunately. I use an alternative keyboard, due to past repetitive stress injury. The quality keyboards out there are several hundred dollars; there aren't many of them, they all have their own shortcomings, and there doesn't seem to be a lot of new innovation in the field lately. Microsoft sells their "Natural Ergonomic Keyboard" for just under $50 as of the time of this writing. That's much more affordable, but it really isn't much better than a standard keyboard, and as a result, the demand for good ergonomic keyboards is almost certainly lower than it would be if Microsoft weren't in the market. So is it better that we can buy the Microsoft Natural Ergonomic Keyboard? You decide.
Before moving on, I'm going to make one brief list of things I can't forget:
- Clippy and the other Office Assistants
- The Browser Wars (Internet Explorer vs. Netscape/Mozilla/Firefox) and their effect on HTML/DOM/Javascript support and compatibility
- Comic Sans and the Screen Beans
- The Office 2007 Ribbon, and other examples of abruptly changing the UI without offering a smooth transition.

Enough. I've said my piece.
MathWorks: the Verdict's Still Out
I started this article by talking about the publish() function in MATLAB. In the last year I've had the opportunity to explore some of the fringes of MATLAB and Simulink, and I'm not sure I'm very pleased. I've already talked a bit about comparing MATLAB to some of the Python libraries. From what I've seen, the core, mainstream, and atypical areas are pretty high-quality. The underlying numerical libraries are really solid, the M-file debugger is great, and Simulink's been around enough, with enough people looking at it, to be reliable. Their customer support, even for the little guy, is very good.
But it's a large and complex software product that has to maintain backward compatibility. Conceptual integrity? Hmm.
I don't know about the publish() function; the markup syntax for publish() seems a little better than that used in Atlassian Confluence, but nowhere near as easy to use or robust as Markdown. I get the impression that it started as a hack or experiment and features gradually got added over time.
Let's look at a few key features:
- Escaping markup syntax: Not mentioned. How do we add * or _ to markup text without triggering bold or italics?
- Robust equation support: It does support LaTeX, which is really great to see, but we've already talked about the bad hash issue, and there's another issue: the images are just included inline, without any vertical alignment information. So if you have an equation like \( \sum\limits_{i=1}^n X_i \), where there is something displayed under the baseline, then it will look out of kilter in a
publish()script, because the resulting HTML doesn't have enough information to place its vertical position correctly. - No support for unicode or HTML entities (e.g.
¶or¶or—) — the backslash and ampersand are escaped prior to emitting HTML output. There is very limited support, outside of LaTeX, for symbols; the only mentioned in the documentation is for the trademark symbols through markup sequences(TM)and(R). And I'm not sure what you can do if you want to actually use a verbatim(TM)in a webpage rather than the trademark symbol ™.
Markdown has been thought out to handle these kind of cases. MATLAB publish() markup has not.
Now, I'm definitely picking on publish() here. You can't pass judgment on a large software product by looking at one small feature. But it's a symptom of running into fringe territory, where a bunch of garden rakes have been left on the ground. As I use MATLAB in future months, I hope this is the exception and not the rule.
I'd appreciate hearing from any of you, if you know of a feature of MATLAB you'd like to point out as a good example — whether it's an example of really solid, robust design, or an example of more garden rakes.
Happy computing in 2014!
© 2014 Jason M. Sachs, all rights reserved.




- Comments
- Write a Comment Select to add a comment
your hash-issue has been solved in R2014B!
it now looks like:
>> hashEquation('aksldfaljkf')
ans =
eq13909385868917450473
--Han
To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:


