



Important Programming Concepts (Even on Embedded Systems) Part VI : Abstraction
Earlier articles:
- Part I: Idempotence
- Part II: Immutability
- Part III: Volatility
- Part IV: Singletons
- Part V: State Machines
We have come to the last part of the Important Programming Concepts series, on abstraction. I thought I might also talk about why there isn’t a Part VII, but decided it would distract from this article — so if you want to know the reason, along with what’s next, you can read it on my personal blog. Anyway, back to abstraction:
Here’s what happens when you talk to a somewhat experienced programmer (SEP) about abstraction layers, and you give them the idea that you’re a newcomer to the whole software engineering thing. The SEP might give you this example, in Java:
public class OrangeContainer
{
public Orange orange;
}
and then tell you that this is bad, because orange is a public field.
Um, so why is it bad? you ask. And you realize you’ve made a mistake, now you’re going to have to listen to this.
“Well,” says the SEP, “It’s just bad. Now everyone expects you to access the orange by orangeContainer.orange forever. What if you wanted to change it and do this:”
public class OrangeContainer
{
public Orange lemon;
}
and then while you’re trying to figure out why you would ever use an object of type Orange called lemon, the SEP says you should be doing this instead:
public interface OrangeContainer
{
public Orange getOrange();
public void setOrange(Orange orange);
}
public class OrangeContainerImpl implements OrangeContainer
{
@Override public Orange getOrange() { return this.lemon; }
@Override public void setOrange(Orange orange) { this.lemon = orange; }
}
This way, says the SEP, with a big grin, you can hide the fact that your Orange is really stored in the field named lemon, and use setOrange() and getOrange() instead. Meanwhile you just wanted to know something about the database abstraction layer you’re using in next month’s software release, and are losing interest rapidly. But the SEP is getting excited about this.
“And you can even do this using generics,” says the SEP:
public interface Container<T>
{
public T get();
public void set(T t);
}
public class OrangeContainerImpl implements Container<Orange>
{
private Orange lemon;
@Override public Orange get() { return this.lemon; }
@Override public void set(Orange orange) { this.lemon = orange; }
}
“Or you could implement it differently....”
public class OrangeContainerImpl implements Container<Orange>
{
final private AtomicReference<Orange> lemonRef = new AtomicReference<Orange>();
@Override public Orange get() { return lemonRef.get(); }
@Override public void set(Orange orange) { this.lemonRef.set(orange); }
}
You say you think the get and set methods are kind of tedious, why not just use the fields directly for something simple like an OrangeContainer, but the SEP is adamant, and mentions that in some languages like JavaScript and Python that there’s support for properties, so when you write orangeContainer.orange it really maps into calls to getter and setter methods, so it looks like you’re accessing the field directly, but really it avoids the badness and now you can rename the storage location of the Orange to lemon without anyone knowing. And there’s a long silence, after which you both walk away.
I could talk about abstraction with this kind of approach, but I won’t, at least not until later. The SEP is right, in a way — abstraction allows you to decouple the inner implementation details from the outward-facing interface — but somehow this seems to me like it misses some important points. Instead of learning the general concepts, we would be stuck in some Java-specific details, and maybe we would split hairs on the differences between abstraction and encapsulation, and you’d become a Somewhat Experienced Programmer yourself and pass along the half-understood concept to the next generation of programmers.
So let’s start over, and talk about something completely different: pattern matching.
Human beings are born pattern-matchers. You take even the most hip, urban, text-message-addicted teenager, and whisk them off into a northern temperate forest sometime in August, and I guarantee, sooner or later, they’ll get hungry and figure out where the blueberries are. But so will the squirrels and the birds and the bears. When we have to, we’ll recognize the patterns. So what’s the difference, and why are we the ones with the sunglasses, vinyl siding, and retirement plans, and not them?
Well, we’re the ones that figured out how to reason about things. It’s one thing to match patterns and find the food. It’s another thing entirely to look at a pattern, and be able to turn that pattern into a thought that describes what that pattern really is. This is one of the essences of abstraction.
We’re going to talk about several of these essences:
- higher-order thinking
- generalization
- simplification
- indirection
Some of these aspects are less interesting or practical than others, and unfortunately the first one probably falls into this category.
1. Taking Shortcuts Into the Air
I like to think the first instance of abstraction in early humans went something like this:
Somewhere, long ago, in a dark cave....
Thorg the Elder: Ok guys, how many rabbits did you guys catch? Ogg?
Ogg: (Takes the lifeless rabbits off his shoulder and puts them onto the ground, and counts.) One, two, three, four. Four!
Thorg the Elder: Good, good. What about you, Zog?
Zog: (Takes the lifeless rabbits off his shoulder and puts them onto the ground, and counts.) One, two, three, four, five. Five!
Thorg the Elder: Excellent! Now what about you, Erk?
Erk the Clever Bully: (Has no rabbits on his shoulder, but quickly snatches up most of the other rabbits, leaving only one each for Ogg and Zog.) One, two, three, four, five, six, seven!
You don’t see the abstraction here? That’s okay, it hasn’t happened yet. Most days in the dark cave went like this. But then one day something important happened:
Thorg the Elder: Ok guys, how many rabbits did you guys catch? Ogg?
Ogg: (Takes the lifeless rabbits off his shoulder and puts them onto the ground, and counts.) One, two, three, four, five, six. Six!
Thorg the Elder: Good, good. What about you, Zog?
Zog: (Takes the lifeless rabbits off his shoulder and puts them onto the ground, and counts.) One, two, three, four. Four!
Thorg the Elder: Excellent! Now what about you, Erk?
Erk the Clever Bully: (Has no rabbits on his shoulder, but quickly snatches up most of the other rabbits, leaving only one each for Ogg and Zog.) Five plus three is eight!
That’s right, someone turned the simple task of counting and incrementing into addition. No need to go one count at a time, when you can recognize that three and four always combine to produce seven, and five and three always combine to produce eight. If Ogg counts 37 blueberries and Zog counts 23 blueberries, Erk can leave them each five blueberries and just add the rest up to get 50 blueberries. Any moment now, Erk will be off starting his own bank and charging outrageous interest rates.

The Ackermann Function: A Really Simple Way to Get a Headache
Warning: this section contains some math that may be hard to grasp. The point isn’t necessarily for you to understand it all; the point is for you to see that there is a spectrum of understanding, from easy to really difficult. If you start to get panicky, just stop reading for a little while, stand up, take a breath, go for a bike ride, play Angry Birds, do whatever you have to do, and then come back. Or skip ahead to the section on times tables if you must. This section is really just about manipulating symbols and patterns, but there’s no penalty for not participating.
Maybe you’ve heard of the Ackermann Function. If not, here it is, a two-input function that takes non-negative integer inputs:
$$ A(m, n) = \begin{cases} n+1 & \mbox{if } m = 0 \cr A(m-1, 1) & \mbox{if } m > 0 \mbox{ and } n = 0 \cr A(m-1, A(m, n-1)) & \mbox{if } m > 0 \mbox{ and } n > 0. \end{cases} $$
The first time you see this, I guarantee you your eyes will glaze over. Mine still do, to some extent.
Computers don’t have any problem evaluating the Ackermann function, though it may take them a long time to do so. And maybe they can manipulate it algebraically, if they’re programmed to do so. But computers can’t understand functions. The only way for a human to understand how a mathematical function works is to explore it, try things, identify patterns, and finally see if we can take a cognitive shortcut to link it to something we already know how to deal with.
So let’s look at \( A(0, n) \). The first line of the function definition tells us directly:
| n | 0 | 1 | 2 | 3 | 4 | … |
|---|---|---|---|---|---|---|
| A(0,n) | 1 | 2 | 3 | 4 | 5 | … |
Okay, now let’s look at \( A(1,n) \). Here we have to look at the last two lines of the function definition. The second line tells us \( A(1,0) = A(0,1) = 2 \). That was easy enough. The third line tells us that \( A(1,n) = A(0, A(1,n-1)) \). Well, we know \( A(0,n) = n+1 \), so this means that \( A(1,n) = A(1,n-1) + 1 \). Oh. To get the value of each output, we take the previous output and add 1, and since we know that \( A(1,0) = 2 \), that tells us that we can generalize through mathematical induction that \( A(1,n) = 2+n \).
| n | 0 | 1 | 2 | 3 | 4 | … |
|---|---|---|---|---|---|---|
| A(0,n) | 1 | 2 | 3 | 4 | 5 | … |
| A(1,n) | 2 | 3 | 4 | 5 | 6 | … |
Now let’s look at \( A(2,n) \). Maybe it’s going to be n+3? We can hope. Okay, from definition line #2 we have \( A(2,0) = A(1,1) = 3 \); that’s a good start. From definition line #3, \( A(2,n) = A(1, A(2, n-1)) \), and since we know \( A(1,n) = n+2 \), this tells us \( A(2,n) = A(2, n-1)) + 2 \). Okay, here we’re skipping ahead by 2 each time, so we can generalize through induction to show that \( A(2,n) = 2n+3 \).
| n | 0 | 1 | 2 | 3 | 4 | … |
|---|---|---|---|---|---|---|
| A(0,n) | 1 | 2 | 3 | 4 | 5 | … |
| A(1,n) | 2 | 3 | 4 | 5 | 6 | … |
| A(2,n) | 3 | 5 | 7 | 9 | 11 | … |
No big deal there. Not what we expected, but not too difficult. Let’s look at \( A(3,n) \). From definition line #2 we have \( A(3,0) = A(2,1) = 5 \). From definition line #3, \( A(3,n) = A(2, A(3, n-1)) \), and since \( A(2,n) = 2n+3 \), this tells us \( A(3,n) = 2 \times A(3,n-1)+3 \). Hmm. Not such an easy thing to generalize. Plug the numbers in, we get 5, 2×5+3 = 13, 2×13+3 = 29, 2×29+3 = 61… maybe we have the insight to notice that if we add 3, we get an exact power of two, so the result is \( A(3,n) = 2^{n+3} - 3 \).
| n | 0 | 1 | 2 | 3 | 4 | … |
|---|---|---|---|---|---|---|
| A(0,n) | 1 | 2 | 3 | 4 | 5 | … |
| A(1,n) | 2 | 3 | 4 | 5 | 6 | … |
| A(2,n) | 3 | 5 | 7 | 9 | 11 | … |
| A(3,n) | 5 | 13 | 29 | 61 | 125 | … |
Okay, how about \( A(4,n) \)? From definition line #2 we have \( A(4,0) = A(3,1) = 13 \). From definition line #3, \( A(4,n) = A(3, A(4, n-1)) \), and since \( A(3,n) = 2^{n+3} - 3 \), this tells us \( A(4,n) = 2^{A(3,n-1)+3}-3 \). Ick. Let’s plug numbers in… 13, \( 2^{16}-3 \) = 65533, \( 2^{2^{16}}-3 \) = some really large number, ugh. We get stacks of \( 2^{2^{2^{…}}}-3 \). This is a mathematical operation called tetration, which has the symbol \( \uparrow\uparrow \), and the results get large very quickly.
| n | 0 | 1 | 2 | 3 | 4 | … |
|---|---|---|---|---|---|---|
| A(0,n) | 1 | 2 | 3 | 4 | 5 | … |
| A(1,n) | 2 | 3 | 4 | 5 | 6 | … |
| A(2,n) | 3 | 5 | 7 | 9 | 11 | … |
| A(3,n) | 5 | 13 | 29 | 61 | 125 | … |
| A(4,n) | 13\( =2^{2^2}-3 \) | 65533\( =2^{2^{2^2}}-3 = 2\uparrow\uparrow 4 - 3 \) | \( 2\uparrow\uparrow 5 - 3 \) | \( 2\uparrow\uparrow 6 - 3 \) | \( 2\uparrow\uparrow 7 - 3 \) | … |
This generalizes using Knuth’s up-arrow notation, to \( A(m,n) = 2\uparrow^{m-2}(n+3) - 3 \) for all \( m \ge 0 \), where \( a \uparrow^{m+1} b \) is defined recursively as
$$a \uparrow^{m+1} b = a \uparrow^m (a \uparrow^m ( a \uparrow^m … (a \uparrow^m a) … ))$$
where the number of \( a \) terms is b, and the base cases are \( a \uparrow^2 b = a \uparrow\uparrow b \), \( a \uparrow^1 b = a \uparrow b = a^b \), \( a \uparrow^0 b = a \times b \), \( a \uparrow^{-1}b = a + b \), and \( a \uparrow^{-2}b = 1+b \).
Whoa. Got a headache yet?
Why Do We Care About Ackermann’s Function?
So why would you want to care about Ackermann’s function, anyway? Well, in most cases, you wouldn’t. It comes up in a discussion of primitive recursive functions, which are basically functions that can be computed using fixed, bounded loops. Ackermann’s function is an example of something that can be defined very simply, that isn’t a primitive recursive function. This is an aspect of computability theory, which tries to answer deep questions about what kinds of results can or can’t be computed using primitive operations (like addition and subtraction) and a series of predetermined steps, and about how long those steps will take. Computability theory is something that mathematicians started thinking about in the late 1920s. It started more or less with Hilbert’s Entscheidungsproblem and the publication of Ackermann’s functions. (Yes, there were more than one of them.) It gave mathematicians like Kurt Gödel, Alonzo Church, and Alan Turing a raison d’être, and their work continued in great earnest for the next few decades, while they waited for computers to finally show up.
Be careful, because if you look into computability theory long enough, the hardcore computer scientists will find you, and you’ll have strange people wearing \( P = NP \) and \( P \neq NP \) t-shirts coming out of the woodwork at parties.
Times tables
Think back to elementary school. You were in second or third grade, and you had to memorize your times tables. Multiplication. Ooh! Such a scary word. It has five syllables. If you’re still reading this article, it probably means that you did a lot better than your classmates, and maybe at the time you understood what multiplication actually means. Some of your classmates probably did not. I can remember a lot of mine had trouble with times tables. Quick: what’s 6 × 7? The thing is, in the grand scheme of things, it’s just a step up a mathematical ladder.
The first rung on the ladder is counting and incrementing. We know how to do this at a very young age. It’s easy to grasp. Look! There are three stones. Add one, and you get four. Add another one, and you get five. What if you have 9,345 stones and someone gives you one more? Well, then of course you have 9,346. The rules for figuring out how to take a number written out in decimal form, and increment it, are pretty easy.
The second rung is addition. You have four stones and someone gives you another three, and then you have a total of 4 + 3 = seven.
The third rung is multiplication. You have a rectangular array of stones that is four rows and three columns, so that means you have a total of 4 × 3 = 12. And here we start to lose people, depending on their age and cognitive ability.
The fourth rung is exponentiation. What’s 43? Well, it’s 64. But what does that mean? Okay, that’s 4 × 4 × 4. There are three fours. Well, that’s how you can calculate it. But what does that really mean? Well, we can use geometry to give it some physical meaning: it’s the volume of a 3-dimensional cube with side four. If you had 52 it would be the area of a 2-dimensional square with side 5. If you had 79 it would be the volume of a 9-dimensional hypercube with side 7. But what about fractional and negative exponents? What does 3.24.71 mean? Or 50.3-7.16? Well, now you get to the idea of exponential growth. We’ve lost the third-graders and most of the world’s nonscientific population at this point. If the a in ab is negative, then you have to deal with complex numbers, and you have really started to lose parallels with tangible things in the real world.
But there are still more rungs in the ladder. This ladder is called hyperoperation, and it includes those \( 2^{2^{2^{2^{…}}}} \) and \( a \uparrow \uparrow b \) and \( a \uparrow \uparrow \uparrow b \) and \( a \uparrow^m b \) things that you avoided if you skipped the section on Ackermann’s function.
At this point the mathematicians are quite content, leaving the rest of us in the dark. These are just mathematical definitions. And here’s the key: they don’t have to correspond to anything with which we have real-world experience! If they do have some real-world significance, that’s great, but you can’t expect it to happen, or expect to rely on your real-world intuition. In abstract mathematics, there are formal definitions, and rules, and you work within the rules, and everything is just fine. You start seeing patterns and the math flows more quickly. Theorems get proven and published all the time; no one gets hurt in the process. Abstraction is just another daily activity.
To sum up: abstraction is a kind of shortcut; there’s a vast body of solved problems in mathematics, and once something is added to it, it can be used in turn for other purposes, allowing mathematicians to build higher castles in the air. The consequence of abstraction, however, is that in many cases the reasoning involved becomes further and further removed from everyday reality.
A mathematician is tired of his job, and decides he wants to join the local fire department.
During the training, he is shown how to use a fireman’s equipment. In one training test, he is shown a burning dumpster. Nearby is a hose, a fire hydrant, and a bucket of water. The mathematician ignores the bucket of water, takes the hose, connects it to the hydrant, turns open the hydrant, and puts out the fire.
“Very good,” says the supervising fireman.
The next test is with a dumpster containing a few smoldering embers. Nearby is a hose, a fire hydrant, and a bucket of water. The mathematician ignores all of these, and climbs into the dumpster where he finds some old newspapers. He carefully blows upon the embers, tearing a few sheets of newspaper and setting them alight. After a few minutes he has a roaring fire going, and he climbs out of the dumpster. He then steps back, and looks at the supervising fireman, expectantly.
“What in heaven’s name has gotten into you?” asks the supervising fireman.
“Very simple,” says the mathematician. “I’ve reduced the situation to a previously solved problem.”
2. Rudolph, the Red-Nosed Pecoran
Okay, time to bring things back to reality. Instead of thinking upwards we’re going to go outwards, and generalize.
Here I’m going to repeat an example I brought up in Part IV, when I talked about singletons:
/**
* horn-bearing mammals of the order Artiodactyla
* and the infraorder Pecora
*/
interface Pecoran
{
public String getFamily();
public String getGenus();
public String getSpecies();
public String getCommonName();
public String getAnimalName();
public String getHornName();
public int getPointCount();
}
abstract class AbstractPecoran implements Pecoran
{
final private String name;
final private int pointCount;
public AbstractPecoran(String name, int pointCount)
{
this.name = name;
this.pointCount = pointCount;
}
@Override public String getAnimalName() { return this.name; }
@Override public int getPointCount() { return this.pointCount; }
}
abstract class Cervid extends AbstractPecoran
{
public Cervid(String name, int pointCount)
{
super(name, pointCount);
}
@Override public String getFamily() { return "Cervidae"; }
@Override public String getHornName() { return "antler"; }
}
class Reindeer extends Cervid
{
public Reindeer(String name, int pointCount)
{
super(name, pointCount);
}
@Override public String getGenus() { return "Rangifer"; }
@Override public String getSpecies() { return "tarandus"; }
@Override public String getCommonName() { return "reindeer"; }
}
class ReindeerGame
{
public void play(Reindeer reindeer)
{
System.out.printf("Reindeer %s has antlers with %d points. Ha ha!\n",
reindeer.getAnimalName(),
reindeer.getPointCount());
}
}
And I mentioned we could generalize the references in ReindeerGame to Reindeer and System.out, so that we could avoid tight coupling to these classes:
class PecoranGame
{
private String capitalize(String s)
{
if (s.isEmpty())
return s;
return s.substring(0, 1).toUpperCase() + s.substring(1);
}
public void play(Pecoran pecoran, PrintStream ps)
{
ps.printf("%s (%s %s) %s has %ss with %d points. Ha ha!\n",
capitalize(pecoran.getCommonName()),
pecoran.getGenus(),
pecoran.getSpecies,
pecoran.getAnimalName(),
pecoran.getHornName(),
pecoran.getPointCount());
}
}
One question to ask is, which is better? A simple pair of classes, Reindeer and ReindeerGame, or a generalized version like the ones shown above?
I guess it depends. If you’re only going to deal with reindeer, there’s not much point in generalizing. But if we started to bring Giraffe and Oryx and Moose into the picture, maybe it makes sense to do so. Generalization is always a tradeoff, and to decide whether to do so, we have to find a way of rationalizing it one way or the other.
Suppose I had a more complex system, that looks something like this:
Giraffe.java 1309 lines
Reindeer.java 1330 lines
Oryx.java 1263 lines
Moose.java 1191 lines
---
total: 5093 lines
I just want to get things done. But I know I might have to add Antelope.java and Sheep.java. Now, it turns out I’ve just hired a recent college graduate. She is reasonably fluent in Java, and is very familiar with computer science and abstraction and all those software engineering things they teach you in school. The stuff that I really need her to do isn’t going to come for another month or two; right now is a perfect opportunity for her to learn the ropes in our project, and maybe to have her try her luck at making things better. So I ask her to refactor my code, and she does it:
Pecoran.java 102 lines (interface)
AbstractPecoran.java 2237 lines (abstract class that implements Pecoran)
Cervid.java 507 lines (inherits from AbstractPecoran)
Bovid.java 545 lines (inherits from AbstractPecoran)
Giraffe.java 820 lines (inherits from AbstractPecoran)
Reindeer.java 307 lines (inherits from Cervid)
Oryx.java 244 lines (inherits from Bovid)
Moose.java 229 lines (inherits from Cervid)
---
total: 4991 lines
OK, now which codebase is better, the four original files, or the seven new files? This is a really hard question. I’d love to show a concrete example and review it in detail, but I don’t have one, and even if I did, some of the details would be distracting. So let’s just stay with some contrived numbers and talk about the situation in general, without (alas) a concrete example to back it up. Here are some things to think about:
-
Total complexity — Assuming we can measure complexity, we could try to evaluate our codebase objectively and quantitatively. If I go by number of lines, we’ve made a modest gain of about 100 lines (2% reduction). Maybe if I’d added
AntelopeandSheepinto the mix first, the situations might have looked like this:Before refactoring: Giraffe.java 1309 lines Reindeer.java 1330 lines Oryx.java 1263 lines Moose.java 1191 lines Antelope.java 1228 lines Sheep.java 1004 lines --- total: 7325 lines After refactoring: Pecoran.java 102 lines (interface) AbstractPecoran.java 2302 lines (abstract class that implements Pecoran) Cervid.java 507 lines (inherits from AbstractPecoran) Bovid.java 680 lines (inherits from AbstractPecoran) Giraffe.java 820 lines (inherits from AbstractPecoran) Reindeer.java 307 lines (inherits from Cervid) Oryx.java 244 lines (inherits from Bovid) Moose.java 229 lines (inherits from Cervid) Antelope.java 260 lines (inherits from Bovid) Sheep.java 170 lines (inherits from Bovid) --- total: 5621 linesNow we have a more significant gain: around 1700 lines (23% reduction), and as our system gets larger, the advantages of refactoring to a set of abstract foundation classes become more apparent. We did have to add some functionality to
AbstractPecoran.javaandBovid.javato handle some of the quirks of theAntelopeandSheepclasses that weren’t there before. So even though the more abstract superclasses got a little more complex, the codebase as a whole got less so. -
Maintenance cost — If I have to make changes to the system, with independent files I have to make the same type of change everywhere, repeating unnecessary effort. In this latest example, I might need to modify (and test!) 500 lines of code in each of the six animal files (total: 3000 lines), whereas after refactoring, maybe I only need to modify 700 lines of code in
AbstractPecoran.java, 200 lines inCervid.java, 150 lines inBovid.java, 80 lines inGiraffe.java, and 30 lines inMoose.java. (total: 1160) — a 60% reduction. Decreases in maintenance work can be huge if I do the right kind of refactoring. -
Cognitive load — We started with a maximum of 1330 lines of code in each animal file, and in each case the class in question is concrete. After refactoring, we have a maximum of 2302 lines of code in
AbstractPecoran.java, and it’s an abstract class, further up in the air and, presumably, harder to understand. In the “before” case, a new programmer would probably find it easier to understand each class, but potentially harder to change these classes in such a way that they maintain their intended commonality, since it’s not an explicit part of the design; if there’s something general about the way we handle horns (maybe this is a computer animation program where we have to draw the animals), they’d have to figure it out themselves. In the “after” case, a new programmer would find it a little bit harder to understand the class hierarchy, but the common behavior would be included explicitly in the design, and it would be easier to change the classes and keep their behavior in sync, most likely changing only one or two superclass files.
In short: refactoring to generalize a software codebase into abstract behavior can turn a large amount of repetitive grungy work that’s prone to errors in consistency, into a smaller amount of challenging work, that might be prone to errors in correctness, though hopefully less error-prone than before. This can usually reduce complexity and maintenance costs, but it takes extra cognitive load to understand the system, and probably extra work up-front to design the system architecture to be more generalized and more abstract.
Even though the Pecoran example is contrived, there are two specific examples from the real world that I’d like to point out.
One is the CreateFile function in the Windows SDK. In my opinion, Microsoft’s APIs have handled generalization badly, and they seem more like brute-force up-against-a-deadline thinking has been at work, rather than careful API design. CreateFile() is used to create or open access to almost any file or I/O device:
The most commonly used I/O devices are as follows: file, file stream, directory, physical disk, volume, console buffer, tape drive, communications resource, mailslot, and pipe. The function returns a handle that can be used to access the file or device for various types of I/O depending on the file or device and the flags and attributes specified.
To perform this operation as a transacted operation, which results in a handle that can be used for transacted I/O, use the
CreateFileTransactedfunction.HANDLE WINAPI CreateFile( _In_ LPCTSTR lpFileName, _In_ DWORD dwDesiredAccess, _In_ DWORD dwShareMode, _In_opt_ LPSECURITY_ATTRIBUTES lpSecurityAttributes, _In_ DWORD dwCreationDisposition, _In_ DWORD dwFlagsAndAttributes, _In_opt_ HANDLE hTemplateFile );
Great, we have a function that takes in 7 arguments. If I just want to open a file for writing (which in most languages or operating systems, takes 2 or 3 arguments, just a filename path and a mode and maybe some flags), I have to mess around with having to know about file-sharing and security attributes. But it is generalized to handle presumably every possible I/O situation. Sometimes generalization goes too far for its own good.
The other example is rather different. This is the Enaml framework for declarative UIs with data binding in Python. I’ve been using it for a few years, and find it really nice to put together some quick prototypes that look pretty slick. It hides a lot of complexity and makes it really easy to design a UI. The one gotcha is if do you ever have to get down into the source code — whether it’s merely to understand what is going on, or to extend it — it can be a little tricky.
The team behind Enaml has done an awesome job keeping APIs simple and straightforward, and it’s pretty well-documented and commented. They’ve even made it possible to be UI-toolkit independent: you can use either wxWidgets or Qt. But the price of this toolkit independence is a dual-tier object model that uses the Proxy pattern. As an example, the enaml.widgets.push_button.PushButton class is a UI widget that handles push buttons. Each instance of the push_button class contains a delegate for an abstract enaml.widgets.ProxyPushButton; this abstract class doesn’t do anything, but its subclasses, which in turn contain a toolkit-dependent object, do the actual work. If you use Qt, then the enaml.qt.qt_push_button.QtPushButton class does the real work, managing a QPushButton from the Qt toolkit. The way the toolkit-specific stuff gets created is handled behind the scenes by proxy resolver factories that go “Oh, you’re using Qt, and since you want a ProxyPushButton, let me create an instance of QtPushButton as the proxy for your PushButton class.”
And each of these classes extend a more abstract class; PushButton extends AbstractButton, ProxyPushButton extends ProxyAbstractButton, QtPushButton extends QtAbstractButton, and QPushButton extends QAbstractButton. The same thing goes for almost all Enaml widges; RadioButton and CheckBox are other examples that extend AbstractButton.
| top-level Enaml widget (E) | abstract proxy (P) | toolkit wrapper (W) | toolkit object (T) |
|---|---|---|---|
AbstractButton | ProxyAbstractButton | QtAbstractButton | QAbstractButton |
PushButton | ProxyPushButton | QtPushButton | QPushButton |
RadioButton | ProxyRadioButton | QtRadioButton | QRadioButton |
CheckBox | ProxyCheckBox | QtCheckBox | QCheckBox |
Each instance of the Enaml widget E contains an instance of a proxy descended from an abstract proxy class P. This proxy class is implemented by a toolkit-specific wrapper class W that contains an instance of the toolkit UI object T. It’s a consistent pattern used in Enaml, and once you catch on, it’s pretty easy to understand. But it’s also really hard to figure out, if you’re a newcomer — and if you want to subclass a widget and add new features in a custom class, or understand where the behavior comes from, sometimes it’s tricky to get all the details right.
Use of abstraction to handle a more general situation has its benefits. Just don’t forget the costs.
These first two aspects of abstractions are examples of pattern matching. Mathematicians see a pattern they can build upon, so they investigate higher-order concepts. (Programmers do this too, especially in the functional world, with concepts like map and fold and filter.) Programmers see a pattern they’ve already used before, so they improve their code by generalizing it and refactoring it to take advantage of repeated structures.
The other two aspects we’re going to talk about, simplification and indirection, are different, and they deal more directly with the idea of abstraction layers, which might be called the I Don’t Care Principle. (Though if you’re dealing with Computer Science-y people, call it an abstraction layer. Or, if you’re feeling confident, the Liskov Substitution Principle, which isn’t completely the same thing we’ll be talking about in the next two sections, but at least that way they’ll know what you’re talking about.) These really get back to what our Somewhat Experienced Programmer (SEP) was talking about with the Orange example. When you are writing software, you need to keep in mind that there’s going to be someone using it, and they don’t really care about all of the implementation details you’re creating.
3. I Don’t Care How Much You Have to Do to Get This Done — Just Get It Done
Simplification is a really fundamental detail of abstraction. In fact, if you think about it, there’s abstraction everywhere in the services we use in daily life. If I wake up in the morning, turn on my computer, check my email messages, and make a cup of tea, I’ve already used maybe five or six abstraction layers:
-
The power company gives me regulated AC voltage in a wall outlet. I just plug in my computer and turn it on, whereas they have to maintain a power grid and keep those generators spinning. But I don’t care about that, I just want to pay my electric bill and plug things into the wall and have them work properly.
-
I have a wireless router in my home, and I just open my web browser to look at
freezingcoldmail.comto read my email messages; in reality, the router uses one of the 802.11 standards to allow data transmission over wireless frequencies in my home. This has a bunch of complicated methods that my computer uses to send packets of data over the Internet via my router. My web browser doesn’t care about this. It connects to a TCP/IP socket on port 80 on some server, and issues a bunch ofGETrequests. The computer’s wireless Ethernet adapter turns this data into a bunch of radiofrequency signals that the router receives and reconstructs into the stream of TCP/IP socket data, which it passes along to a bunch of other computers until the mail server on the other end responds to theGETrequests with an HTML page, that my web browser renders into something that looks like an email client. And I don’t care about theGETrequests, or even where the servers forfreezingcoldmail.comactually are located. I just want to connect tofreezingcoldmail.comand see my email. -
Water comes out of my faucet. The city water company gives me a supply of water when I need it. They maintain the pipes to my house and the reservoirs and the water treatment plants. I don’t care what they are doing, I just want to pay my water bill and get potable water when I need it.
-
I bought some tea at the grocery store. It comes in little filter paper bags in a box. I just go on the shelf and find it and bring it to the cash register. The tea company goes out and finds the appropriate ingredients and dries them and mixes them together in the right proportions, and packages them up and distributes them to grocery stores. And when I swipe my credit card to the cashier at the grocery store, the point-of-sale device goes out somehow and talks to VISA or Mastercard and they do this dance with my bank to put a charge on next month’s bill and credit the grocery store. But I don’t care about any of this, I just want to pay the grocery store money so I can buy some more tea. (And it all works fine, until Stash Tea decides to discontinue Lemon Blossom Tea and the system breaks down. :-( Boo. )
You get the point. The important thing here is that an abstraction is a sort of a contract agreed upon by multiple parties to keep services happening smoothly. People came up with standards on what AC power actually needs to be, and what is acceptable for potable water, and how credit card transactions and 802.11 and HTTP work. Somebody designed them and somebody else built systems that meet those standards. What actually goes on behind the scenes is either a semantic detail dictated by the standards, or is an implementation detail that is up to the service provider.
So, yeah, you can make an OrangeContainer class which has a public orange field. But just be aware that if you need to do something complicated behind the scenes, you should probably create an abstraction to simplify it and specify what’s relevant.
In software design, this means you need to think about what details are really the important essence of what you need, versus what are implementation details. If you want a key-value pair to look up a bunch of things by name, don’t specify what type of database you feel like using today, or whether you want to store the information in a hash map or use B-trees or whatever. That’s not important. Boil it down to the essence of what you need. Leave the rest as an implementation detail. Because when you write something into the definition of your abstraction layer, you are essentially writing yourself a contract, and the more detail you put into it, the less freedom you have to fulfill that contract.
As an employee in the semiconductor industry (in case you’ve forgotten, I work at Microchip as an applications engineer; standard disclaimer: the opinions expressed here are my own and not representative of my employer), I find it really interesting to work with our architects on new product and new peripheral definitions. The abstraction layer that you see when you use a microcontroller is the information expressed in the datasheet. This is an edited description of what the architects write up when they define the instruction set, the peripherals, and the overall behavior of a microcontroller, along with characterization data obtained during testing. What’s in the document written by the architects is semantically equivalent, but the registers may have different names, and there may be proprietary information about business motivation (e.g. how much die area is expected among different alternative implementations for a peripheral) that won’t be in the datasheet. Or a feature is described and implemented, but during testing it is decided that the feature will not be supported, so it doesn’t go into the datasheet. On the implementation side, we have silicon designers that take the architects’ documents and create some arrangement of transistors that does what we need it to do. When you write assembly code that executes a MOV instruction, what actually happens is some set of multiplexers kick in and enable data to flow from some part of the chip onto another part of the chip. But that’s not something we allow our customers to access; you get to write the MOV instruction in an assembly program according to the documented instruction set, and we will make sure it happens correctly.
Finally I want to point out one nuance of abstraction using Figures 13 and 14 from Harel’s statechart paper that I mentioned in Part V:
Figure 13:
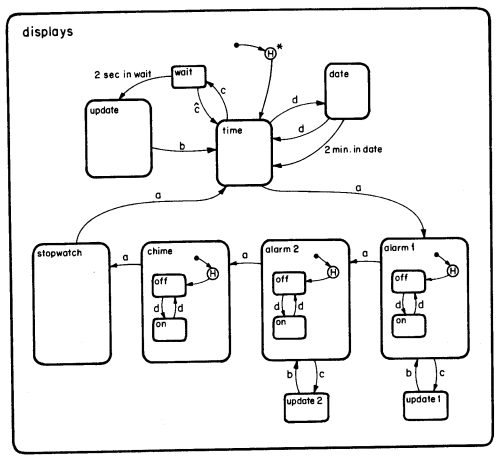
Figure 14:
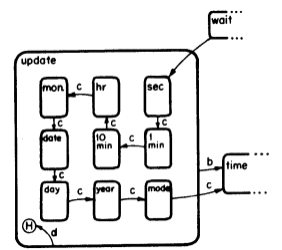
You’ll note that in Figure 13, the update substate is a small opaque block, which is shown in more detail in Figure 14. In Figure 13 we see only an abstract, simplified view of this substate. Sometimes you need to view a system in less detail, so defining its behavior in that less-detailed view is just as important as the detailed picture of its operation.
4. I Don’t Care Who Actually Does the Work — Just Get It Done
The last aspect of abstraction I want to cover is indirection.
I worked on a power conversion project a few years back. The main designer of this system used Altium for schematic design and layout. He also used its hierarchical schematic features, perhaps because he had a strong software engineering background, where concepts like Don’t Repeat Yourself (DRY) are commonly used. Here’s how the hierarchical schematic feature worked. Let’s say that on page 7 that included current sensing, instead of a couple of op-amps and some resistors and capacitors, there were two big green rectangles, each marked Current Sensing, with some input and output ports. And on page 12 was the circuit design for the Current Sensing block, with the op-amps and resistors and capacitors, and input and output ports. So on page 7, there were really two instances of each of the components on page 12, it’s just that instead of placing them directly on page 7, they were utilized indirectly, by referencing page 12.
The software engineer in me loved this idea. You never have to worry about the two instances of Current Sensing being identical. The schematic program makes sure they are. Make a change to the Current Sensing circuit and it will automatically be updated in both places. And the layout program can even replicate some of the layout features for both instances. Hurray!
But at the same time, I kind of hated it — because every time I wanted to find out what was really happening in the circuit, instead of seeing it on one circuit page, part of it was in the top level page (the one with Current Sensing abstracted as a big green rectangle), and part of it was lower down in the hierarchy on the Current Sensing page, and I had to flip back and forth. And this was part of a 30- or 40-page schematic. I could never remember which page was the Current Sensing page, so I had to write down the page numbers. Some of the circuits spanned three or four levels of the hierarchy.
In short: conceptual units of the schematic had been encapsulated as an abstraction layer, and referred indirectly to another section now on a separate page. Abstraction was helping guarantee correctness, but hindering my “holistic” understanding of how things worked.
I run into the same kind of issue from time to time in software design. I remember one motor control circuit board that my project team contracted out to a design house. They did a great job doing the circuit design. We told them what we wanted, then reviewed and guided the schematic and layout as they designed it. It made our job easier; we reduced the amount of time we spent doing all the work, and delegated the rest to the design house, so that we could focus on other parts of our system. They sent out the circuit board to be manufactured, and they soldered the components on it and did some low-level testing, even writing some C-language device drivers for us. And there my praise stops. Because their code looked something like this:
current_sensing.h:
#include "foo.h"
float getMotorCurrent()
{
return adcVoltage[ADC_CHAN_MOTOR_CURRENT]*AMPS_PER_COUNT;
}
foo.h:
#include "bsp.h"
#define AMPS_PER_COUNT ((FULLSCALE_AMPS)/32768)
bsp.h:
#define CS_R1 50e3
#define CS_R2 5e3
#define CS_Rs 0.01
#define FULLSCALE_AMPS ((FULLSCALE_ADC_VOLT)/(CS_R1/CS_R2*CS_Rs))
#define FULLSCALE_ADC_VOLT 2.048
only their code was worse, spanning four or five #include files. I wanted to figure out the full-scale current they were using in their code, so I could make sure that it correctly matched the behavior of the hardware, but it was tedious and time-consuming. The opposite effect of magic numbers came into play: instead of cryptic numbers that were immediately visible, there were several levels of indirection that defined the software gains. One #define was in the C code, and it depended on another #define as a formula in a header file, which depended on more #defined formulas in other header files, and the formulas looked kind of correct, and the numbers in the header files were directly relatable to circuit component values, and if you flipped back and forth among the different header files and rooted around in the circuit design to compare against the schematic, they seemed to be right. But sometimes there were bugs, and they were really hard to find and fix.
With modern IDEs this process is a bit easier; in NetBeans and PyCharm I can click on a function name and press Ctrl+B, and it will navigate directly to the source of that function. I don’t have to search manually through files to find the right definition. But it’s still a little tedious to check certain things. There are some aspects of system design where you have to punch through the abstraction layer, and see how the low-level implementation inside the abstraction interacts with items outside the abstraction. In a well-designed abstraction, this shouldn’t matter much. But that’s really hard to get perfect.
In any case, this obfuscated aspect of hierarchically-structured code is one of the downsides of abstraction. The up-side is that the person who implements an abstraction layer has a great deal of freedom to make things work, and can create several abstraction layers between the outermost layer and where work actually gets done. If I have a matrix multiply operation, the code that actually executes the multiply can be anywhere. I might even used an FFT-based routine for large matrices. And the place where data is actually stored can be almost anywhere. Ever try to debug C++ code using the Standard Template Library, like a std::map<std::string, std::vector<std::string>>? If you have to write code to manipulate maps of vectors of strings, it’s really easy. If you have to look in a debugger at the values within that data structure, however, it can be really difficult. You see things like pair<K_, Ty_> and you go lower and lower and lower in layers of indirection until finally you get to the data you want to see. Maybe the debuggers nowadays can make this process easier, but when I used C++, it was like being lost in a maze of twisty little passages.
But there I go again pointing out negatives. Indirection is really a positive thing. It’s how you decouple modular subsystems in the real world. Instead of all the code and data being together in one place in a fixed layout, where there’s no freedom to reorganize, we use dynamic pointers and indices and references, so things can be moved around at runtime. I don’t know exactly where my power comes from. It might be from one of several nearby power plants, and the power company has the freedom to change it from one instant to the next. Same with the grocery store. I don’t know which farm the potatoes come from. The store display might tell me they’re from Maine or Idaho, but that’s it. The grocery store has the freedom to shop around and get them from different places as the supply and demand shifts. In fact, the grocery store itself probably doesn’t know where the potatoes come from; they work with a produce wholesaler to get the potatoes. There’s no reason there couldn’t be a chain of 10 separate people (farmer A sells to company B sells to company C … sells to grocery store J) between me and the potato farm, as long as it meets the cost and availability requirements of the grocery store. If I want to buy potatoes from one specific farm, or get my power from one specific source, I can’t work with the normal system of things; I’d have to bypass the abstraction layer, and make arrangements myself, and life would be more complicated.
What Does All This Mean for the Embedded System?
A lot of what’s become part of good software design practices in the past few decades is more difficult to use in a resource-limited embedded system that uses plain C or at most some features of C++. Dynamic memory allocation is usually off-limits for reasons of nondeterministic behavior, and that removes features like the Standard Template Library. Levels of abstraction usually come with some overhead (unless the compiler can optimize that overhead out) in execution time, code and data usage, or communication bandwidth.
But a lot of the things that facilitate good abstraction layers are available to the C programmer.
Functions should access data through indirect access (as I mentioned in Part IV) and have knowledge only of the types they need. If I have modules M1 and M2, and they do separate things, then they shouldn’t share data types if they don’t need to. Something like this is not preferable, because it ties the data types together:
/* main_system.h */
typedef struct
{
int16_t u;
int16_t x;
} M1_state;
typedef struct
{
int16_t y;
} M2_state;
typedef struct
{
M1_state m1;
M2_state m2;
} M1M2_state;
/* m1.h */
#include "main_system.h"
void m1_doit(M1M2_state *pm1m2);
/* m1.c */
#include "m1.h"
void m1_doit(M1M2_state *pm1m2)
{
pm1m2->m1.x = f1(pm1m2->m1.u);
}
/* m2.h */
#include "main_system.h"
void m2_doit(M1M2_state *pm1m2);
/* m2.c */
#include "m2.h"
void m2_doit(M1M2_state *pm1m2)
{
pm1m2->m2.y = f2(pm1m2->m1.x);
}
/* main_system.c */
M1M2_state m1m2_state
m1_doit(&m1m2_state);
m2_doit(&m1m2_state);
Here we have one big data structure of type M1M2_state, and we pass a pointer to it to every function that needs to calculate something. Each of those functions grabs what it needs as inputs, and updates what it needs as outputs. What could be wrong with that?
Well, unfortunately, now we need each module to know about the M1M2_state, and every time we need to add an implementation detail, we have to update M1M2_state and recompile the whole mess. If we add module M3, maybe we need to change the name to M1M2M3_state, and at some point we just change it to BigUglyStateStructure or BUSS.
Instead, this alternative keeps the modules separate:
/* m1.h */
typedef struct
{
int16_t u;
int16_t x;
} M1_state;
void m1_doit(M1_state *pm1);
/* m1.c */
#include "m1.h"
void m1_doit(M1_state *pm1)
{
pm1->x = f1(pm1->u);
}
/* m2.h */
typedef struct
{
int16_t x;
int16_t y;
} M2_state;
void m2_doit(M2_state *pm2);
/* m2.c */
#include "m2.h"
void m2_doit(M2_state *pm2)
{
pm2->y = f2(pm2->x);
}
/* main_system.h */
#include "m1.h"
#include "m2.h"
typedef struct
{
M1_state m1;
M2_state m2;
} M1M2_state;
/* main_system.c */
M1M2_state m1m2_state;
m1_doit(&m1m2_state.m1);
m1m2_state.m2.x = m1m2_state.m1.x;
m2_doit(&m1m2_state.m2);
Here the only place where we care about M1M2_state or the Big Ugly State Structure is in the top-level module. Each of the modules sees only its own inputs and outputs. To take this route, we require an extra copy of x, taking a little bit more data memory and more computation time, but as a result, there are no ties between M1 and M2, and we can change them separately to our heart’s content.
But the most important part of the design of abstraction layers isn’t so much the low-level details like these, but rather the high-level partitioning of a system. It’s much easier to figure out a good system architecture at a high level, and then implement the details.
Of course, I usually have a different strategy, depending on the frequency of computation. If something is executed on a timescale perceptible to people (say, 50 milliseconds or more), then I ignore any impulse for optimization, and do whatever makes sense for good software practices. If I’ve got a high-speed control loop running at 1000Hz or more, then I have to keep an eye on how things actually work at the low levels, and the purely black-box approach of abstraction isn’t always possible.
Shim Layers
One common use of abstraction found in many systems (including embedded ones) is the concept of a shim layer or facade. Think back to the grocery store example I mentioned earlier, about buying potatoes. Let’s say we have three parties: a farmer and a wholesaler and the grocery store. The wholesaler is just a middleman, right? We don’t really need him, we can just have the grocery store work directly with the potato farmer. The consumer isn’t going to know in any case; they just buy from the grocery store. So why not cut out the middleman?
Well, the wholesaler does some important work here. For one, the wholesaler business helps handle transportation between the potato farm and the grocery store. Perhaps more importantly, the wholesaler deals with farmers and handles all their quirks. Don’t get me wrong. I like farmers. If someone feels that they simply must drop a bomb on my corner of the world, I want them to drop it on the used car lot or the advertising agency, not the farmer’s field. But I’ve met a few farmers, and they can be a bit odd. So from the grocery store’s point of view, the wholesaler is essentially making the farmers all look the same. And the same thing with the grocery stores and their weird contracts and requirements. The wholesaler makes all the grocery stores look the same to the farmer. And don’t forget, the potato farmer might get sick, or sell his land to become a used car lot — the wholesaler may need to switch farmers. You get the idea. So we need those wholesalers.
In software design, shim layers and facades perform a similar function. They essentially help join two main pieces of our system, a high-level application, and a low-level library, without them having to be directly coupled together. They don’t really add any overhead except a function call (which the compiler can optimize out, for example in C if the functions are declared inline static in a header file) to take the inputs and set them up the way the low-level library needs to see. My team is currently working on a hardware abstraction layer, to allow us to write application software that can work with several different development boards, and part of it is a shim layer so that we can more easily adapt to changes in our low-level library. Another example of shims: those of you using Java may be familiar with slf4j, which is a really small logging facade layer that allows an application programmer to switch easily between one of several logging libraries like java.util.logging, log4j, and logback.
Shim layers. Another instance of abstraction. Yeah!
Wrapup
In this article, we’ve talked a bit about some of the diverse aspects of abstraction.
- Pattern-matching and reuse
- Higher-order operations — taking a lower-level concept and reusing it to do something more complex
- Generalization — taking multiple instances that have similarities, and extracting common factors so that the common elements can be reused and maintained in one place
- Abstraction layers and the I-Don’t-Care Principle / Liskov Substitution Principle
- Simplification — implementation details aren’t important from the standpoint of the consumer; instead, abstraction layers should be thought of as a contract, and should cover only the minimum set of simplified details required for two entities to interact
- Indirection — abstraction allows the real computations to be performed by any entity hidden from the consumer, not just the one the consumer is directly interacting with.
Abstraction is a powerful concept, and can save you time and headaches the next time you design software, if you use it correctly and put the effort into it. A well-designed set of abstractions in software looks natural and is easy to use — though it probably took a lot of work.
Thanks for reading!
© 2015 Jason M. Sachs, all rights reserved.




- Comments
- Write a Comment Select to add a comment
To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:



